In the recent past, using machine learning (ML) to make predictions, especially for data in the form of text and images, required extensive ML knowledge for creating and tuning of deep learning models. Today, ML has become more accessible to any user who wants to use ML models to generate business value. With Amazon SageMaker Canvas, you can create predictions for a number of different data types beyond just tabular or time series data without writing a single line of code. These capabilities include pre-trained models for image, text, and document data types.
In this post, we discuss how you can use pre-trained models to retrieve predictions for supported data types beyond tabular data.
Text data
SageMaker Canvas provides a visual, no-code environment for building, training, and deploying ML models. For natural language processing (NLP) tasks, SageMaker Canvas integrates seamlessly with Amazon Comprehend to allow you to perform key NLP capabilities like language detection, entity recognition, sentiment analysis, topic modeling, and more. The integration eliminates the need for any coding or data engineering to use the robust NLP models of Amazon Comprehend. You simply provide your text data and select from four commonly used capabilities: sentiment analysis, language detection, entities extraction, and personal information detection. For each scenario, you can use the UI to test and use batch prediction to select data stored in Amazon Simple Storage Service (Amazon S3).

Sentiment analysis
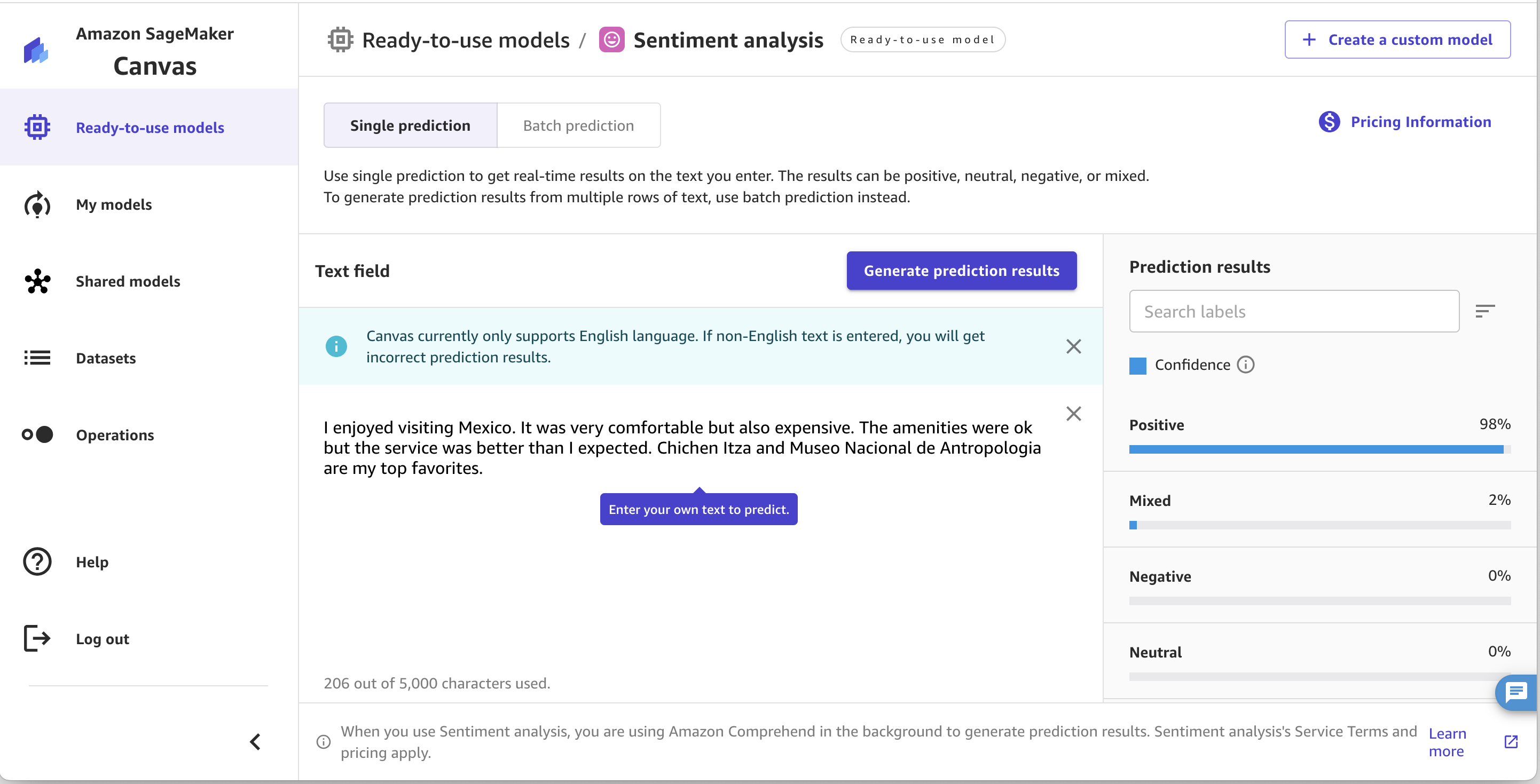
With sentiment analysis, SageMaker Canvas allows you to analyze the sentiment of your input text. It can determine if the overall sentiment is positive, negative, mixed, or neutral, as shown in the following screenshot. This is useful in situations like analyzing product reviews. For example, the text “I love this product, it’s amazing!” would be classified by SageMaker Canvas as having a positive sentiment, whereas “This product is horrible, I regret buying it” would be labeled as negative sentiment.
Entities extraction
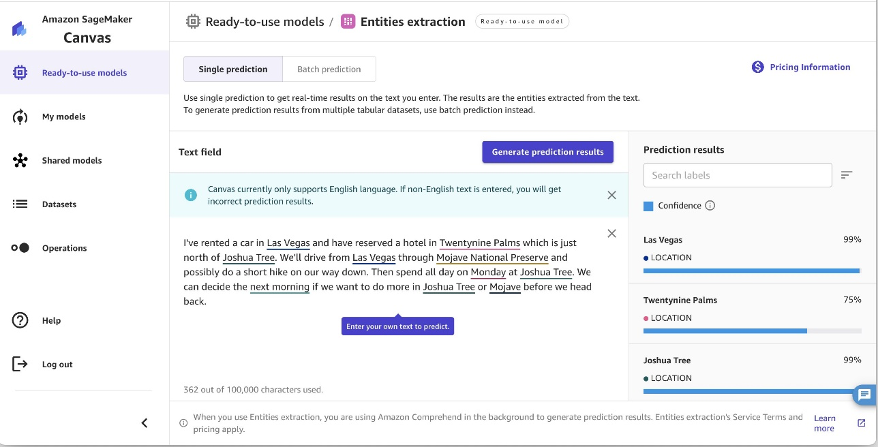
SageMaker Canvas can analyze text and automatically detect entities mentioned within it. When a document is sent to SageMaker Canvas for analysis, it will identify people, organizations, locations, dates, quantities, and other entities in the text. This entity extraction capability enables you to quickly gain insights into the key people, places, and details discussed in documents. For a list of supported entities, refer to Entities.
Language detection
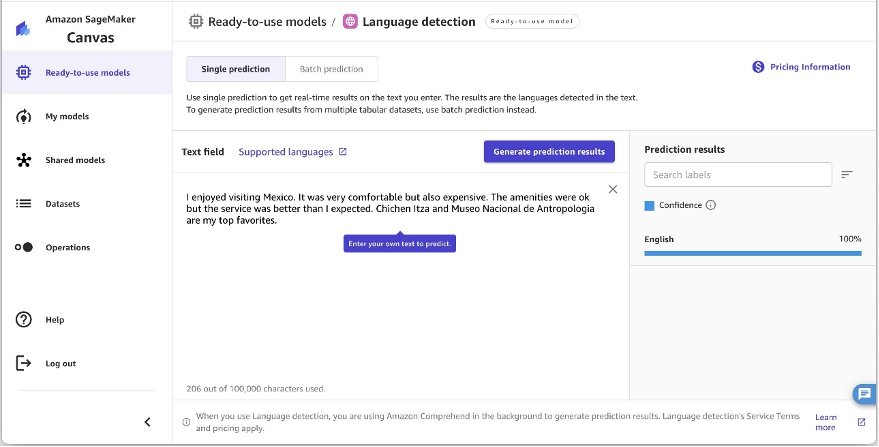
SageMaker Canvas can also determine the dominant language of text using Amazon Comprehend. It analyzes text to identify the main language and provides confidence scores for the detected dominant language, but doesn’t indicate percentage breakdowns for multilingual documents. For best results with long documents in multiple languages, split the text into smaller pieces and aggregate the results to estimate language percentages. It works best with at least 20 characters of text.
Personal information detection
You can also protect sensitive data using personal information detection with SageMaker Canvas. It can analyze text documents to automatically detect personally identifiable information (PII) entities, allowing you to locate sensitive data like names, addresses, dates of birth, phone numbers, email addresses, and more. It analyzes documents up to 100 KB and provides a confidence score for each detected entity so you can review and selectively redact the most sensitive information. For a list of entities detected, refer to Detecting PII entities.
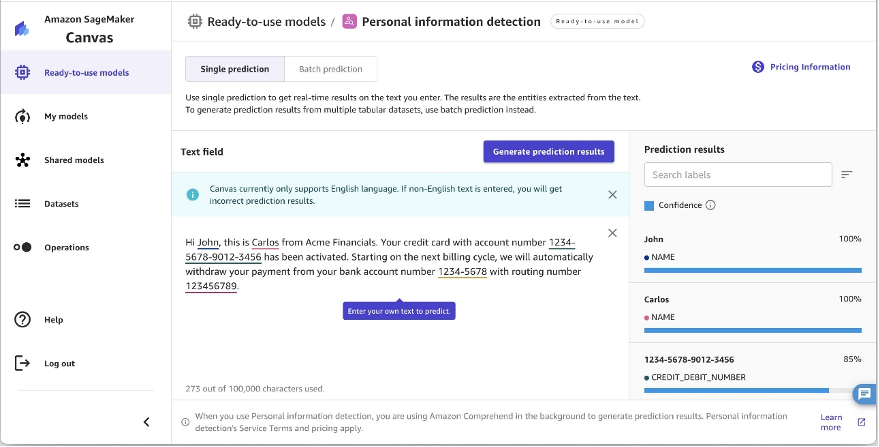
Image data
SageMaker Canvas provides a visual, no-code interface that makes it straightforward for you to use computer vision capabilities by integrating with Amazon Rekognition for image analysis. For example, you can upload a dataset of images, use Amazon Rekognition to detect objects and scenes, and perform text detection to address a wide range of use cases. The visual interface and Amazon Rekognition integration make it possible for non-developers to harness advanced computer vision techniques.
Object detection in images
SageMaker Canvas uses Amazon Rekognition to detect labels (objects) in an image. You can upload the image from the SageMaker Canvas UI or use the Batch Prediction tab to select images stored in an S3 bucket. As shown in the following example, it can extract objects in the image such as clock tower, bus, buildings, and more. You can use the interface to search through the prediction results and sort them.
Text detection in images
Extracting text from images is a very common use case. Now, you can perform this task with ease on SageMaker Canvas with no code. The text is extracted as line items, as shown in the following screenshot. Short phrases within the image are classified together and identified as a phrase.
You can perform batch predictions by uploading a set of images, extract all the images in a single batch job, and download the results as a CSV file. This solution is useful when you want to extract and detect text in images.
Document data
SageMaker Canvas offers a variety of ready-to-use solutions that solve your day-to-day document understanding needs. These solutions are powered by Amazon Textract. To view all the available options for documents, choose to Ready-to-use models in the navigation pane and filter by Documents, as shown in the following screenshot.
Document analysis
Document analysis analyzes documents and forms for relationships among detected text. The operations return four categories of document extraction: raw text, forms, tables, and signatures. The solution’s capability of understanding the document structure gives you extra flexibility in the type of data you want to extract from the documents. The following screenshot is an example of what table detection looks like.
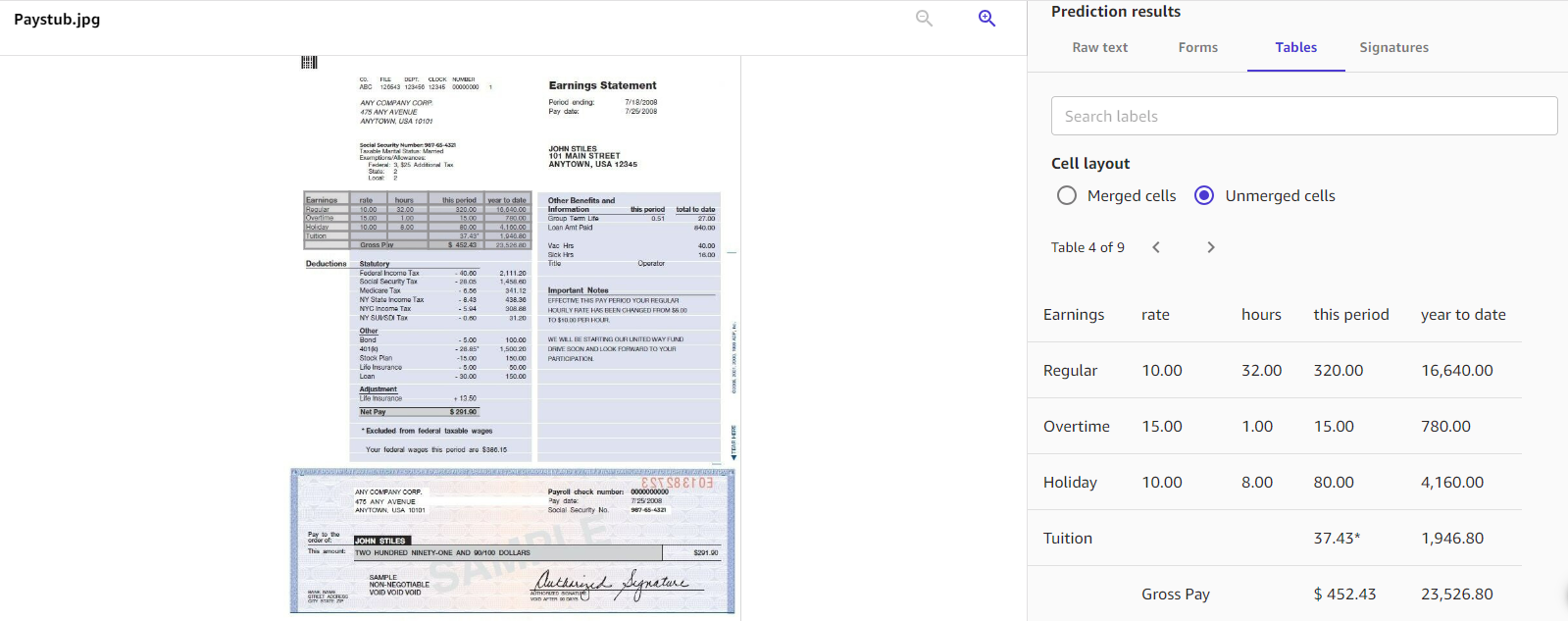
This solution is able to understand layouts of complex documents, which is helpful when you need to extract specific information in your documents.
Identity document analysis
This solution is designed to analyze documents like personal identification cards, driver’s licenses, or other similar forms of identification. Information such as middle name, county, and place of birth, together with its individual confidence score on the accuracy, will be returned for each identity document, as shown in the following screenshot.
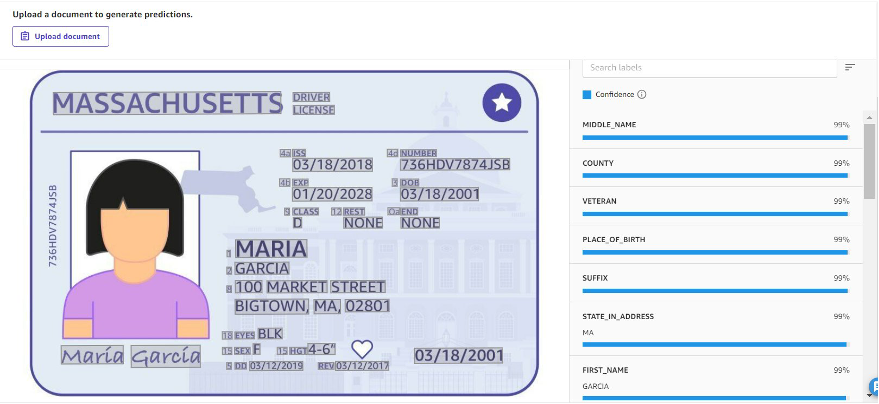
There is an option to do batch prediction, whereby you can bulk upload sets of identification documents and process them as a batch job. This provides a quick and seamless way to transform identification document details into key-value pairs that can be used for downstream processes such as data analysis.
Expense analysis
Expense analysis is designed to analyze expense documents like invoices and receipts. The following screenshot is an example of what the extracted information looks like.
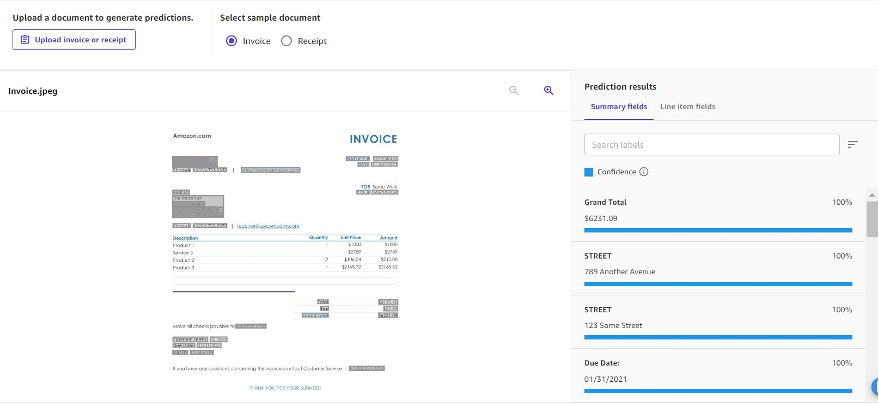
The results are returned as summary fields and line item fields. Summary fields are key-value pairs extracted from the document, and contain keys such as Grand Total, Due Date, and Tax. Line item fields refer to data that is structured as a table in the document. This is useful for extracting information from the document while retaining its layout.
Document queries
Document queries are designed for you to ask questions about your documents. This is a great solution to use when you have multi-page documents and you want to extract very specific answers from your documents. The following is an example of the types of questions you can ask and what the extracted answers look like.
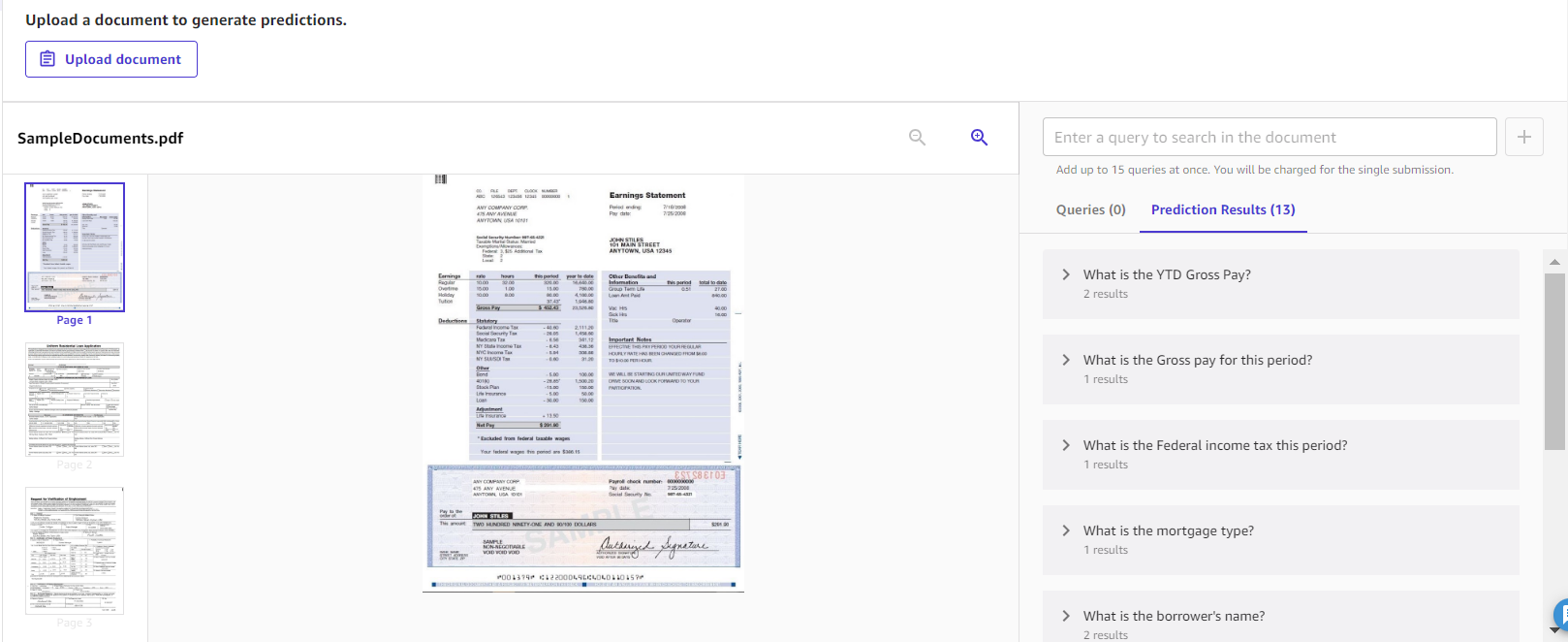
The solution provides a straightforward interface for you to interact with your documents. This is helpful when you want to get specific details within large documents.
Conclusion
SageMaker Canvas provides a no-code environment to use ML with ease across various data types like text, images, and documents. The visual interface and integration with AWS services like Amazon Comprehend, Amazon Rekognition, and Amazon Textract eliminates the need for coding and data engineering. You can analyze text for sentiment, entities, languages, and PII. For images, object and text detection enables computer vision use cases. Finally, document analysis can extract text while preserving its layout for downstream processes. The ready-to-use solutions in SageMaker Canvas make it possible for you to harness advanced ML techniques to generate insights from both structured and unstructured data. If you’re interested using no-code tools with ready-to-use ML models, try out SageMaker Canvas today. For more information, refer to Getting started with using Amazon SageMaker Canvas.
About the authors
 Julia Ang is a Solutions Architect based in Singapore. She has worked with customers in a range of fields, from health and public sector to digital native businesses, to adopt solutions according to their business needs. She has also been supporting customers in Southeast Asia and beyond to use AI & ML in their businesses. Outside of work, she enjoys learning about the world through traveling and engaging in creative pursuits.
Julia Ang is a Solutions Architect based in Singapore. She has worked with customers in a range of fields, from health and public sector to digital native businesses, to adopt solutions according to their business needs. She has also been supporting customers in Southeast Asia and beyond to use AI & ML in their businesses. Outside of work, she enjoys learning about the world through traveling and engaging in creative pursuits.
 Loke Jun Kai is a Specialist Solutions Architect for AI/ML based in Singapore. He works with customer across ASEAN to architect machine learning solutions at scale in AWS. Jun Kai is an advocate for Low-Code No-Code machine learning tools. In his spare time, he enjoys being with the nature.
Loke Jun Kai is a Specialist Solutions Architect for AI/ML based in Singapore. He works with customer across ASEAN to architect machine learning solutions at scale in AWS. Jun Kai is an advocate for Low-Code No-Code machine learning tools. In his spare time, he enjoys being with the nature.





