
Photo by Scott Webb on Unsplash
Determining the value of housing is a classic example of using machine learning (ML). A significant influence was made by Harrison and Rubinfeld (1978), who published a groundbreaking paper and dataset that became known informally as the Boston housing dataset. This seminal work proposed a method for estimating housing prices as a function of numerous dimensions, including air quality, which was the principal focus of their research. Almost 50 years later, the estimation of housing prices has become an important teaching tool for students and professionals interested in using data and ML in business decision-making.
In this post, we discuss the use of an open-source model specifically designed for the task of visual question answering (VQA). With VQA, you can ask a question of a photo using natural language and receive an answer to your question—also in plain language. Our goal in this post is to inspire and demonstrate what is possible using this technology. We propose using this capability with the Amazon SageMaker platform of services to improve regression model accuracy in an ML use case, and independently, for the automated tagging of visual images.
We provide a corresponding YouTube video that demonstrates what is discussed here. Video playback will start midway to highlight the most salient point. We suggest you follow this reading with the video to reinforce and gain a richer understanding of the concept.
Foundation models
This solution centers on the use of a foundation model published to the Hugging Face model repository. Here, we use the term foundation model to describe an artificial intelligence (AI) capability that has been pre-trained on a large and diverse body of data. Foundation models can sometimes be ready to use without the burden of training a model from zero. Some foundation models can be fine-tuned, which means teaching them additional patterns that are relevant to your business but missing from the original, generalized published model. Fine-tuning is sometimes needed to deliver correct responses that are unique to your use case or body of knowledge.
In the Hugging Face repository, there are several VQA models to choose from. We selected the model with the most downloads at the time of this writing. Although this post demonstrates the ability to use a model from an open-source model repository, the same concept would apply to a model you trained from zero or used from another trusted provider.
A modern approach to a classic use case
Home price estimation has traditionally occurred through tabular data where features of the property are used to inform price. Although there can be hundreds of features to consider, some fundamental examples are the size of the home in the finished space, the number of bedrooms and bathrooms, and the location of the residence.
Machine learning is capable of incorporating diverse input sources beyond tabular data, such as audio, still images, motion video, and natural language. In AI, the term multimodal refers to the use of a variety of media types, such as images and tabular data. In this post, we show how to use multimodal data to find and liberate hidden value locked up in the abundant digital exhaust produced by today’s modern world.
With this idea in mind, we demonstrate the use of foundation models to extract latent features from images of the property. By utilizing insights found in the images, not previously available in the tabular data, we can improve the accuracy of the model. Both the images and tabular data discussed in this post were originally made available and published to GitHub by Ahmed and Moustafa (2016).
A picture is worth a thousand words
Now that we understand the capabilities of VQA, let’s consider the two following images of kitchens. How would you assess the home’s value from these images? What are some questions you would ask yourself? Each picture may elicit dozens of questions in your mind. Some of those questions may lead to meaningful answers that improve a home valuation process.
 |
 |
Photos credit Francesca Tosolini (L) and Sidekix Media (R) on Unsplash
The following table provides anecdotal examples of VQA interactions by showing questions alongside their corresponding answers. Answers can come in the form of categorical, continuous value, or binary responses.
| Example Question | Example Answer from Foundation Model |
| What are the countertops made from? | granite, tile, marble, laminate, etc. |
| Is this an expensive kitchen? | yes, no |
| How many separated sinks are there? | 0, 1, 2 |
Reference architecture
In this post, we use Amazon SageMaker Data Wrangler to ask a uniform set of visual questions for thousands of photos in the dataset. SageMaker Data Wrangler is purpose-built to simplify the process of data preparation and feature engineering. By providing more than 300 built-in transformations, SageMaker Data Wrangler helps reduce the time it takes to prepare tabular and image data for ML from weeks to minutes. Here, SageMaker Data Wrangler combines data features from the original tabular set with photo-born features from the foundation model for model training.
Next, we build a regression model with the use of Amazon SageMaker Canvas. SageMaker Canvas can build a model, without writing any code, and deliver preliminary results in as little as 2–15 minutes. In the section that follows, we provide a reference architecture used to make this solution guidance possible.
Many popular models from Hugging Face and other providers are one-click deployable with Amazon SageMaker JumpStart. There are hundreds of thousands of models available in these repositories. For this post, we choose a model not available in SageMaker JumpStart, which requires a customer deployment. As shown in the following figure, we deploy a Hugging Face model for inference using an Amazon SageMaker Studio notebook. The notebook is used to deploy an endpoint for real-time inference. The notebook uses assets that include the Hugging Face binary model, a pointer to a container image, and a purpose-built inference.py script that matches the model’s expected input and output. As you read this, the mix of available VQA models may change. The important thing is to review available VQA models, at the time you read this, and be prepared to deploy the model you choose, which will have its own API request and response contract.
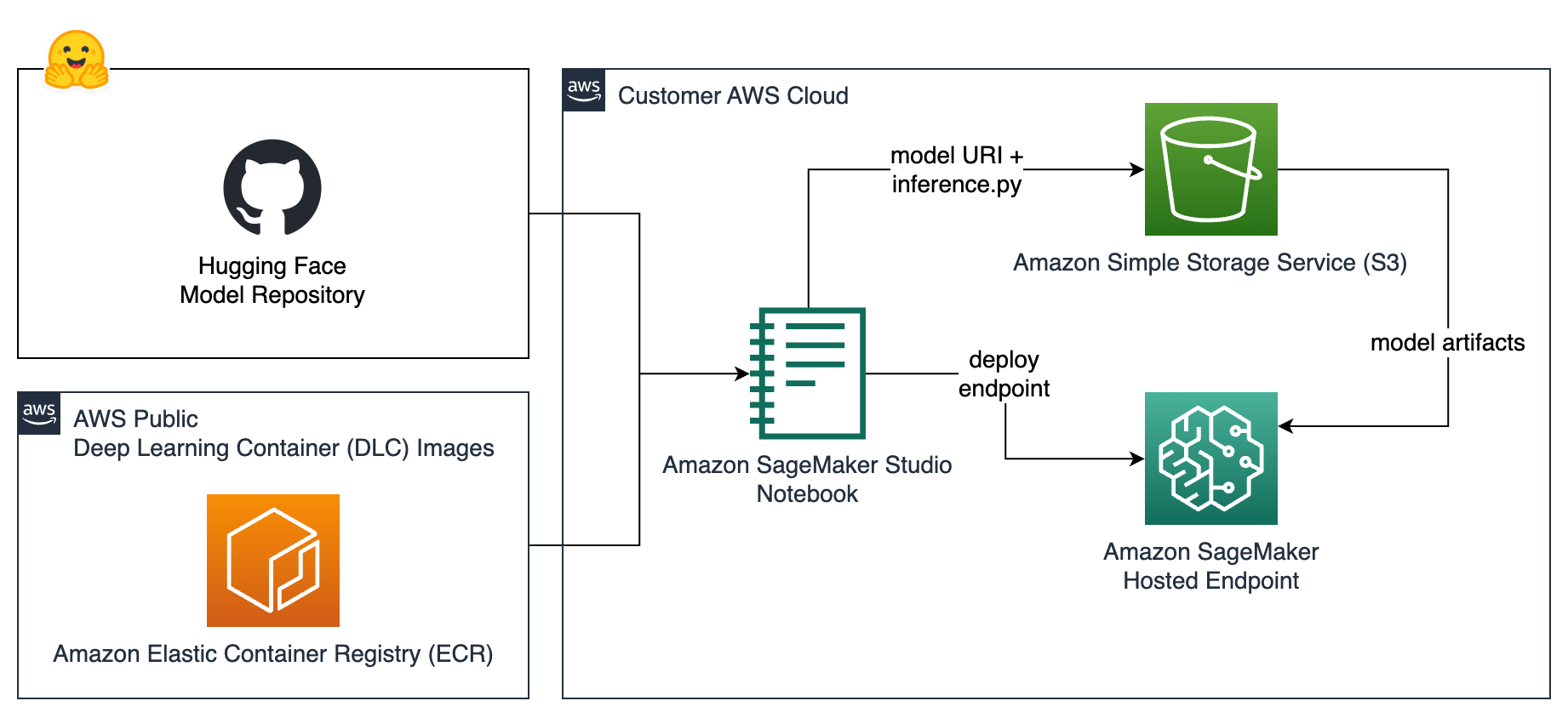
After the VQA model is served by the SageMaker endpoint, we use SageMaker Data Wrangler to orchestrate the pipeline that ultimately combines tabular data and features extracted from the digital images and reshape the data for model training. The next figure offers a view of how the full-scale data transformation job is run.
In the following figure, we use SageMaker Data Wrangler to orchestrate data preparation tasks and SageMaker Canvas for model training. First, SageMaker Data Wrangler uses Amazon Location Service to convert ZIP codes available in the raw data into latitude and longitude features. Second, SageMaker Data Wrangler is able to coordinate sending thousands of photos to a SageMaker hosted endpoint for real-time inference, asking a uniform set of questions per scene. This results a rich array of features that describe characteristics observed in kitchens, bathrooms, home exteriors, and more. After data has been prepared by SageMaker Data Wrangler, a training data set is available in Amazon Simple Storage Service (Amazon S3). Using the S3 data as an input, SageMaker Canvas is able to train a model, in as little as 2–15 minutes, without writing any code.
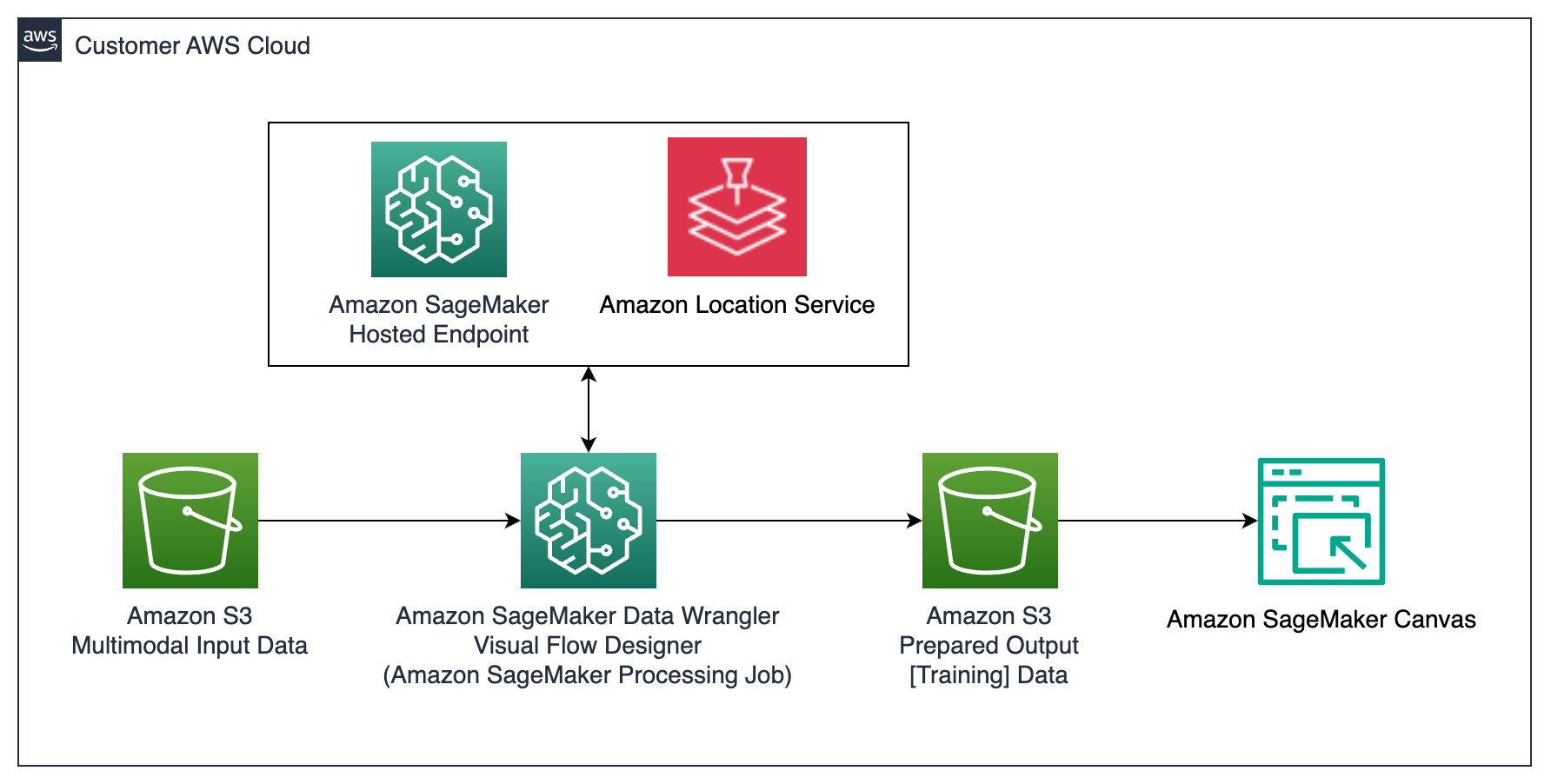
Data transformation using SageMaker Data Wrangler
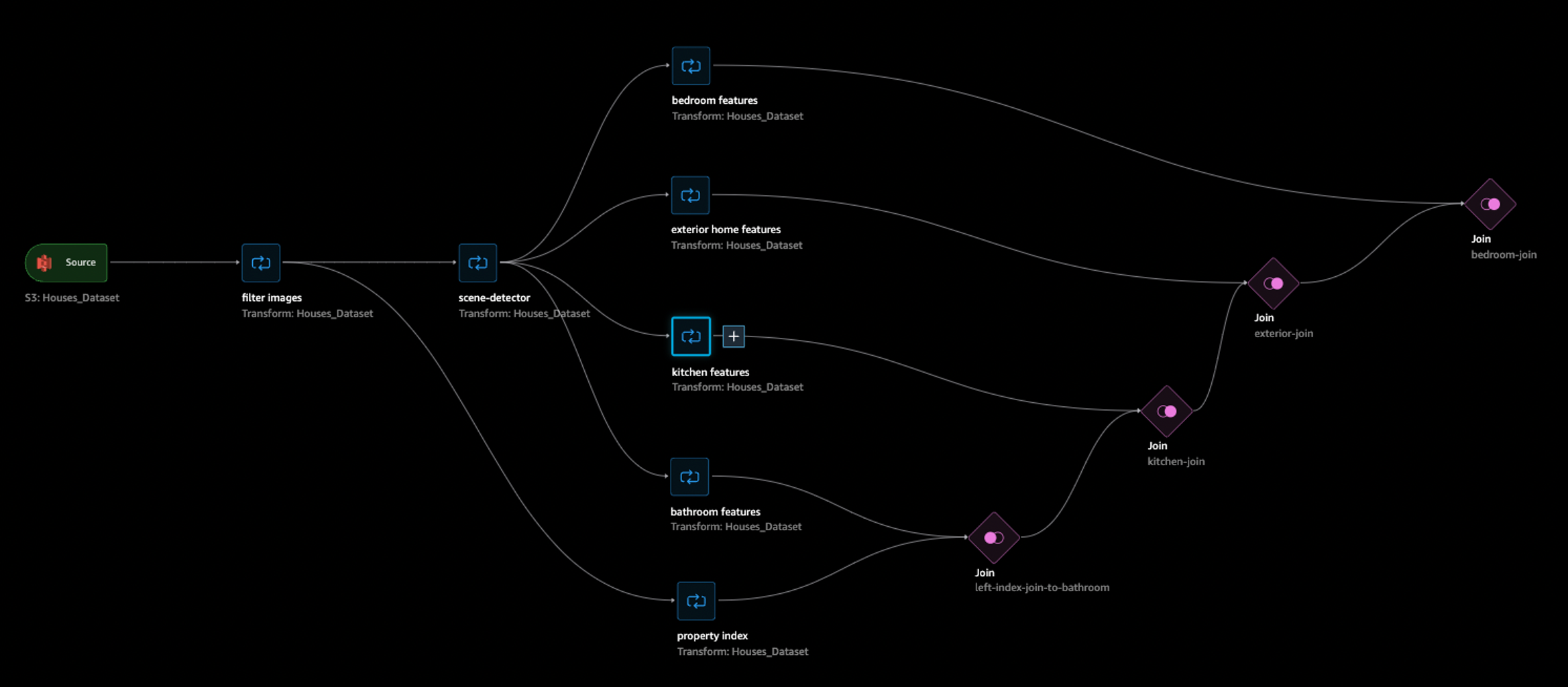
The following screenshot shows a SageMaker Data Wrangler workflow. The workflow begins with thousands of photos of homes stored in Amazon S3. Next, a scene detector determines the scene, such as kitchen or bathroom. Finally, a scene-specific set of questions are asked of the images, resulting in a richer, tabular dataset available for training.
The following is an example of the SageMaker Data Wrangler custom transformation code used to interact with the foundation model and obtain information about pictures of kitchens. In the preceding screenshot, if you were to choose the kitchen features node, the following code would appear:
As a security consideration, you must first enable SageMaker Data Wrangler to call your SageMaker real-time endpoint through AWS Identity and Access Management (IAM). Similarly, any AWS resources you invoke through SageMaker Data Wrangler will need similar allow permissions.
Data structures before and after SageMaker Data Wrangler
In this section, we discuss the structure of the original tabular data and the enhanced data. The enhanced data contains new data features relative to this example use case. In your application, take time to imagine the diverse set of questions available in your images to help your classification or regression task. The idea is to imagine as many questions as possible and then test them to make sure they do provide value-add.
Structure of original tabular data
As described in the source GitHub repo, the sample dataset contains 535 tabular records including four images per property. The following table illustrates the structure of the original tabular data.
| Feature | Comment |
| Number of bedrooms | . |
| Number of bathrooms | . |
| Area (square feet) | . |
| ZIP Code | . |
| Price | This is the target variable to be predicted. |
Structure of enhanced data
The following table illustrates the enhanced data structure, which contains several new features derived from the images.
| Feature | Comment |
| Number of bedrooms | . |
| Number of bathrooms | . |
| Area (square feet) | . |
| Latitude | Computed by passing original ZIP code into Amazon Location Service. This is the centroid value for the ZIP. |
| Longitude | Computed by passing original ZIP code into Amazon Location Service. This is the centroid value for the ZIP. |
| Does the bedroom contain a vaulted ceiling? | 0 = no; 1 = yes |
| Is the bathroom expensive? | 0 = no; 1 = yes |
| Is the kitchen expensive? | 0 = no; 1 = yes |
| Price | This is the target variable to be predicted. |
Model training with SageMaker Canvas
A SageMaker Data Wrangler processing job fully prepares and makes the entire tabular training dataset available in Amazon S3. Next, SageMaker Canvas addresses the model building phase of the ML lifecycle. Canvas begins by opening the S3 training set. Being able to understand a model is often a key customer requirement. Without writing code, and within a few clicks, SageMaker Canvas provides rich, visual feedback on model performance. As seen in the screenshot in the following section, SageMaker Canvas shows the how single features inform the model.
Model trained with original tabular data and features derived from real-estate images
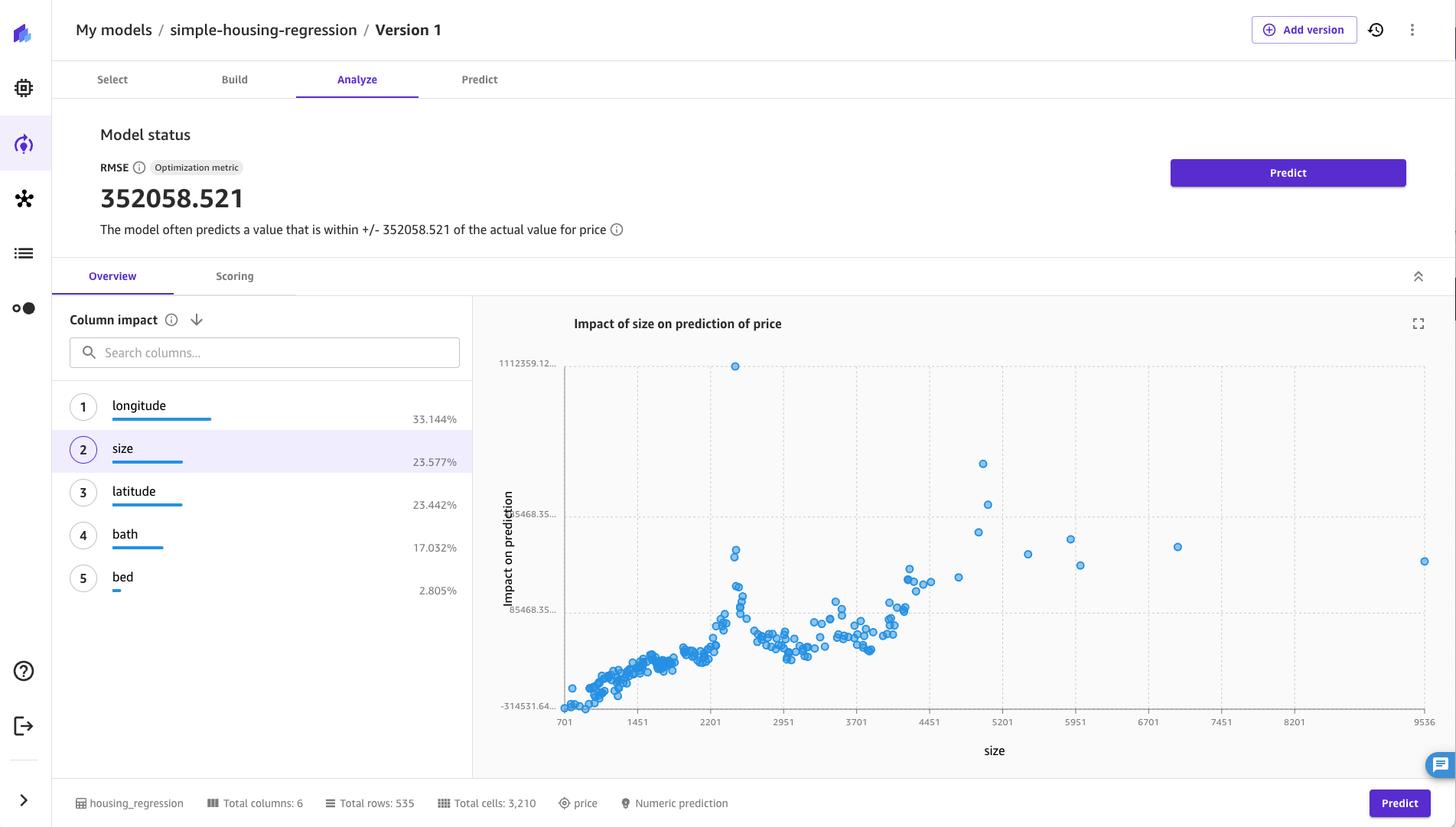
We can see from the following screenshot that features developed from images of the property were important. Based on these results, the question “Is this kitchen expensive” from the photo was more significant than “number of bedrooms” in the original tabular set, with feature importance values of 7.08 and 5.498, respectively.
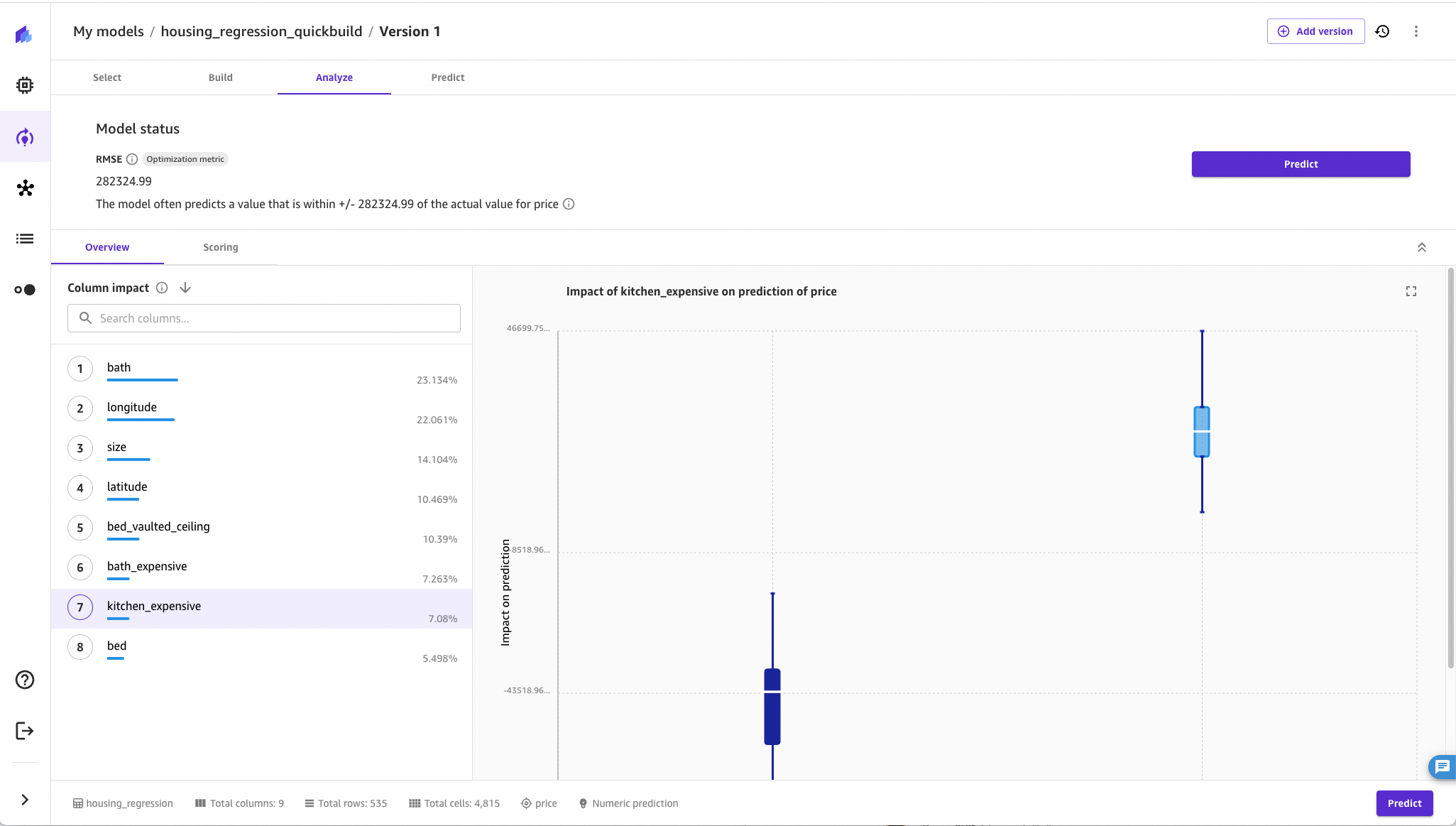
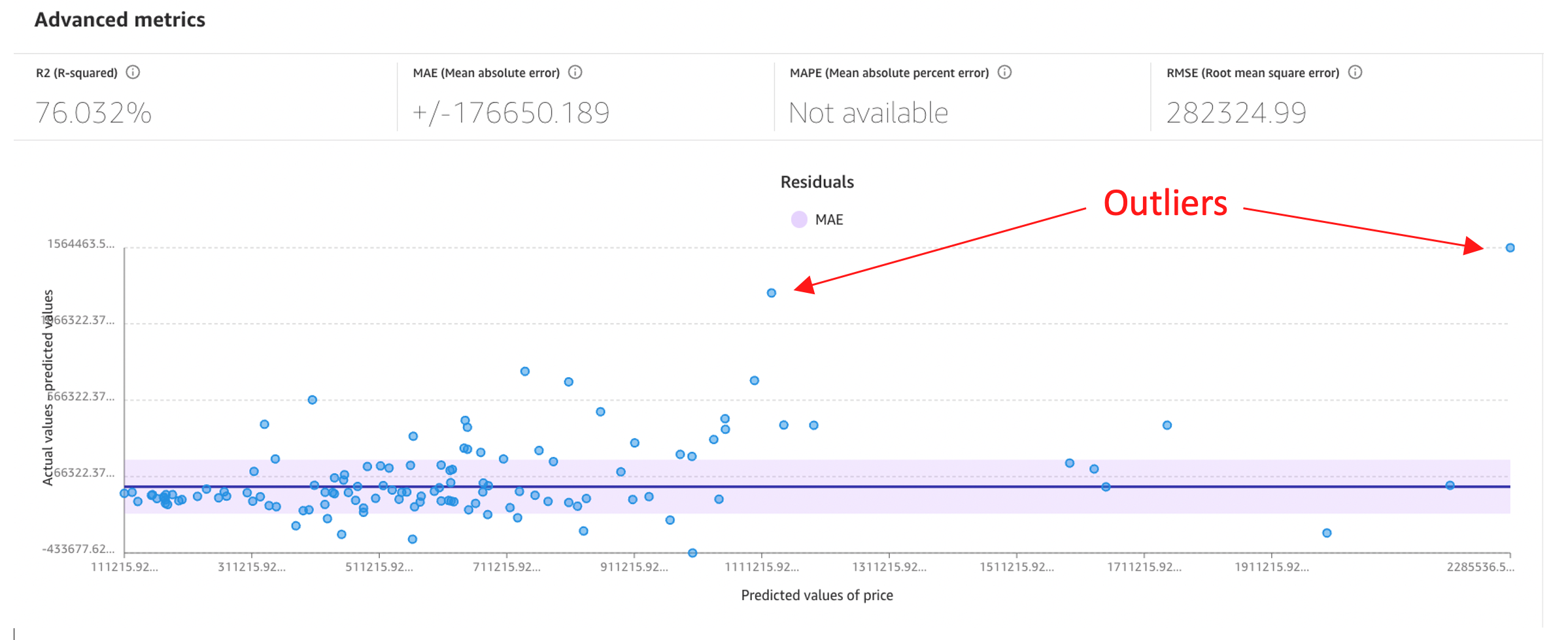
The following screenshot provides important information about the model. First, the residual graph shows most points in the set clustering around the purple shaded zone. Here, two outliers were manually annotated outside SageMaker Canvas for this illustration. These outliers represent significant gaps between the true home value and the predicted value. Additionally, the R2 value, which has a possible range of 0–100%, is shown at 76%. This indicates the model is imperfect and doesn’t have enough information points to fully account for all the variety to fully estimate home values.
We can use outliers to find and propose additional signals to build a more comprehensive model. For example, these outlier properties may include a swimming pool or be located on large plots of land. The dataset didn’t include these features; however, you may be able to locate this data and train a new model with “has swimming pool” included as an additional feature. Ideally, on your next attempt, the R2 value would increase and the MAE and RMSE values would decrease.
Model trained without features derived from real-estate images
Finally, before moving to the next section, let’s explore if the features from the images were helpful. The following screenshot provides another SageMaker Canvas trained model without the features from the VQA model. We see the model error rate has increased, from an RMSE of 282K to an RMSE of 352K. From this, we can conclude that three simple questions from the images improved model accuracy by about 20%. Not shown, but to be complete, the R2 value for the following model deteriorated as well, dropping to a value of 62% from a value of 76% with the VQA features provided. This is an example of how SageMaker Canvas makes it straightforward to quickly experiment and use a data-driven approach that yields a model to serve your business need.
Looking ahead
Many organizations are becoming increasingly interested in foundation models, especially since general pre-trained transformers (GPTs) officially became a mainstream topic of interest in December 2022. A large portion of the interest in foundation models is centered on large language models (LLM) tasks; however, there are other diverse use cases available, such as computer vision and, more narrowly, the specialized VQA task described here.
This post is an example to inspire the use of multimodal data to solve industry use cases. Although we demonstrated the use and benefit of VQA in a regression model, it can also be used to label and tag images for subsequent search or business workflow routing. Imagine being able to search for properties listed for sale or rent. Suppose you want a find a property with tile floors or marble countertops. Today, you might have to get a long list of candidate properties and filter yourself by sight as you browse through each candidate. Instead, imagine being able to filter listings that contain these features—even if a person didn’t explicitly tag them. In the insurance industry, imagine the ability to estimate claim damages, or route next actions in a business workflow from images. In social media platforms, photos could be auto-tagged for subsequent use.
Summary
This post demonstrated how to use computer vision enabled by a foundation model to improve a classic ML use case using the SageMaker platform. As part of the solution proposed, we located a popular VQA model available on a public model registry and deployed it using a SageMaker endpoint for real-time inference.
Next, we used SageMaker Data Wrangler to orchestrate a workflow in which uniform questions were asked of the images in order to generate a rich set of tabular data. Finally, we used SageMaker Canvas to train a regression model. It’s important to note that the sample dataset was very simple and, therefore, imperfect by design. Even so, SageMaker Canvas makes it easy to understand model accuracy and seek out additional signals to improve the accuracy of a baseline model.
We hope this post has encouraged you use the multimodal data your organization may possess. Additionally, we hope the post has inspired you to consider model training as an iterative process. A great model can be achieved with some patience. Models that are near-perfect may be too good to be true, perhaps the result of target leakage or overfitting. An ideal scenario would begin with a model that is good, but not perfect. Using errors, losses, and residual plots, you can obtain additional data signals to increase the accuracy from your initial baseline estimate.
AWS offers the broadest and deepest set of ML services and supporting cloud infrastructure, putting ML in the hands of every developer, data scientist, and expert practitioner. If you’re curious to learn more about the SageMaker platform, including SageMaker Data Wrangler and SageMaker Canvas, please reach out to your AWS account team and start a conversation. Also, consider reading more about SageMaker Data Wrangler custom transformations.
References
Ahmed, E. H., & Moustafa, M. (2016). House price estimation from visual and textual features. IJCCI 2016-Proceedings of the 8th International Joint Conference on Computational Intelligence, 3, 62–68.
Harrison Jr, D., & Rubinfeld, D. L. (1978). Hedonic housing prices and the demand for clean air. Journal of environmental economics and management, 5(1), 81-102.
Kim, W., Son, B. & Kim, I.. (2021). ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. Proceedings of the 38th International Conference on Machine Learning, in Proceedings of Machine Learning Research. 139:5583-5594.
About The Author
 Charles Laughlin is a Principal AI/ML Specialist Solution Architect and works in the Amazon SageMaker service team at AWS. He helps shape the service roadmap and collaborates daily with diverse AWS customers to help transform their businesses using cutting-edge AWS technologies and thought leadership. Charles holds a M.S. in Supply Chain Management and a Ph.D. in Data Science.
Charles Laughlin is a Principal AI/ML Specialist Solution Architect and works in the Amazon SageMaker service team at AWS. He helps shape the service roadmap and collaborates daily with diverse AWS customers to help transform their businesses using cutting-edge AWS technologies and thought leadership. Charles holds a M.S. in Supply Chain Management and a Ph.D. in Data Science.





