Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Custom Queries provides a way for you to customize the Queries feature for your business-specific, non-standard documents such as auto lending contracts, checks, and pay statements, in a self-service way. By customizing the feature to recognize the unique terms, structures, and key information specific to these document types, you can meet your downstream processing needs with greater precision and minimal human intervention. Custom Queries is easy to integrate in your existing Textract pipeline and you continue to benefit from the fully managed intelligent document processing features of Amazon Textract without having to invest in ML expertise or infrastructure management.
In this post, we show how Custom Queries can accurately extract data from checks that are complex, non-standard documents. In addition, we discuss the benefits of Custom Queries and share best practices for effectively using this feature.
Solution overview
When starting with a new use case, you can evaluate how Textract Queries performs on your documents by navigating to the Textract console and using the Analyze Document Demo or Bulk Document Uploader. Refer to Best Practices for Queries to draft queries applicable to your use case. If you identify errors in the query responses due to the nature of your business documents, you can use Custom Queries to improve accuracy. Within hours, you can annotate your sample documents using the AWS Management Console and train an adapter. Adapters are components that plug in to the Amazon Textract pre-trained deep learning model, customizing its output based on your annotated documents. You can use the adapter for inference by passing the adapter identifier as an additional parameter to the Analyze Document Queries API request.
Let’s examine how Custom Queries can improve extraction accuracy in a challenging real-world scenario such as extraction of data from checks. The primary challenge when processing checks arises from their high degree of variation depending on the type (e.g., personal or cashier’s checks), financial institution and country (e.g., MICR line format). . These variations can include the placement of the payee’s name, the amount in numbers and words, the date, and the signature. Recognizing and adapting to these variations can be a complex task during data extraction. To improve data extraction, organizations often employ manual verification and validation processes, which increases the cost and time of the extraction process.
Custom Queries addresses these challenges by enabling you to customize the pre-trained Queries features on the different variations of checks. Customization of the pre-trained feature helps you achieve a high data extraction accuracy on the specific variety of layouts that you process.
In our use case, a financial institution wants to extract the following fields from a check: payee name, payer name, account number, routing number, payment amount (in numbers), payment amount (in words), check number, date, and memo.
Let’s explore the process of generating an adapter (component that customizes the output) for checks processing. Adapters can be created via the console or programmatically via the API. This post details the console experience; however, if you’d like to programmatically create the adapter, refer to the code samples in the custom-queries-checks-blog.ipynb Jupyter notebook (Option 2).
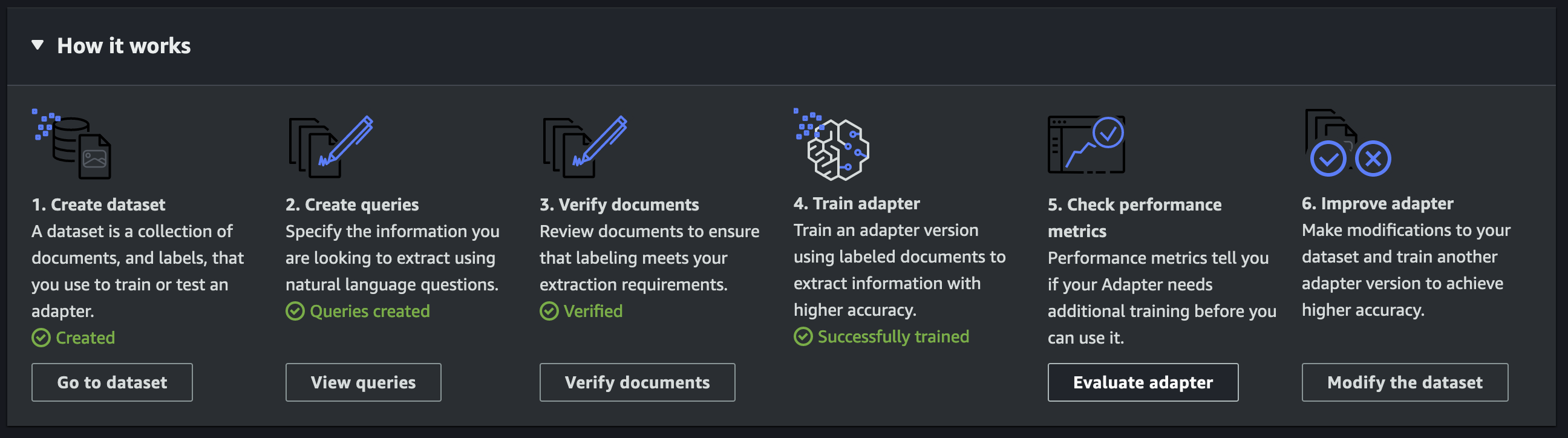
The adapter generation process involves five high-level steps: create an adapter, upload sample documents, annotate the documents, train the adapter, and evaluate performance metrics.
Create an adapter
On the Amazon Textract console, create a new adapter by providing a name, description, and optional tags that can help you identify the adapter. You have the option to enable automatic updates, which allows Amazon Textract to update your adapter when the underlying Queries feature is updated with new capabilities.
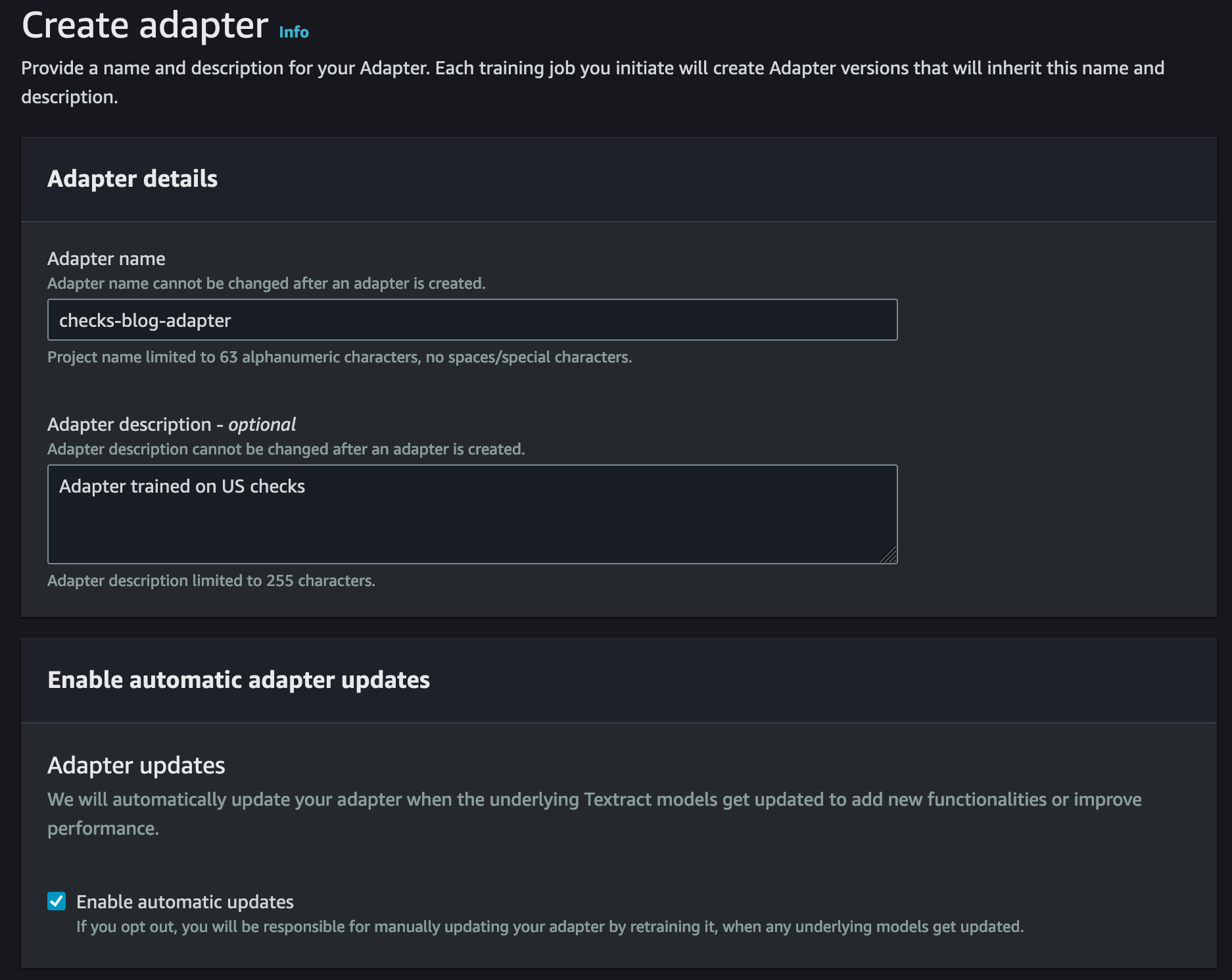
After the adapter is created, you will see an adapter details page with a list of steps in the How it works section. This section will activate your next steps as you complete them sequentially.

Upload sample documents
The initial phase in adapter generation involves the careful selection of an appropriate set of sample documents for annotation, training, and testing. We have an option to auto split the documents into test and train datasets; however, for this process, we manually split the dataset.
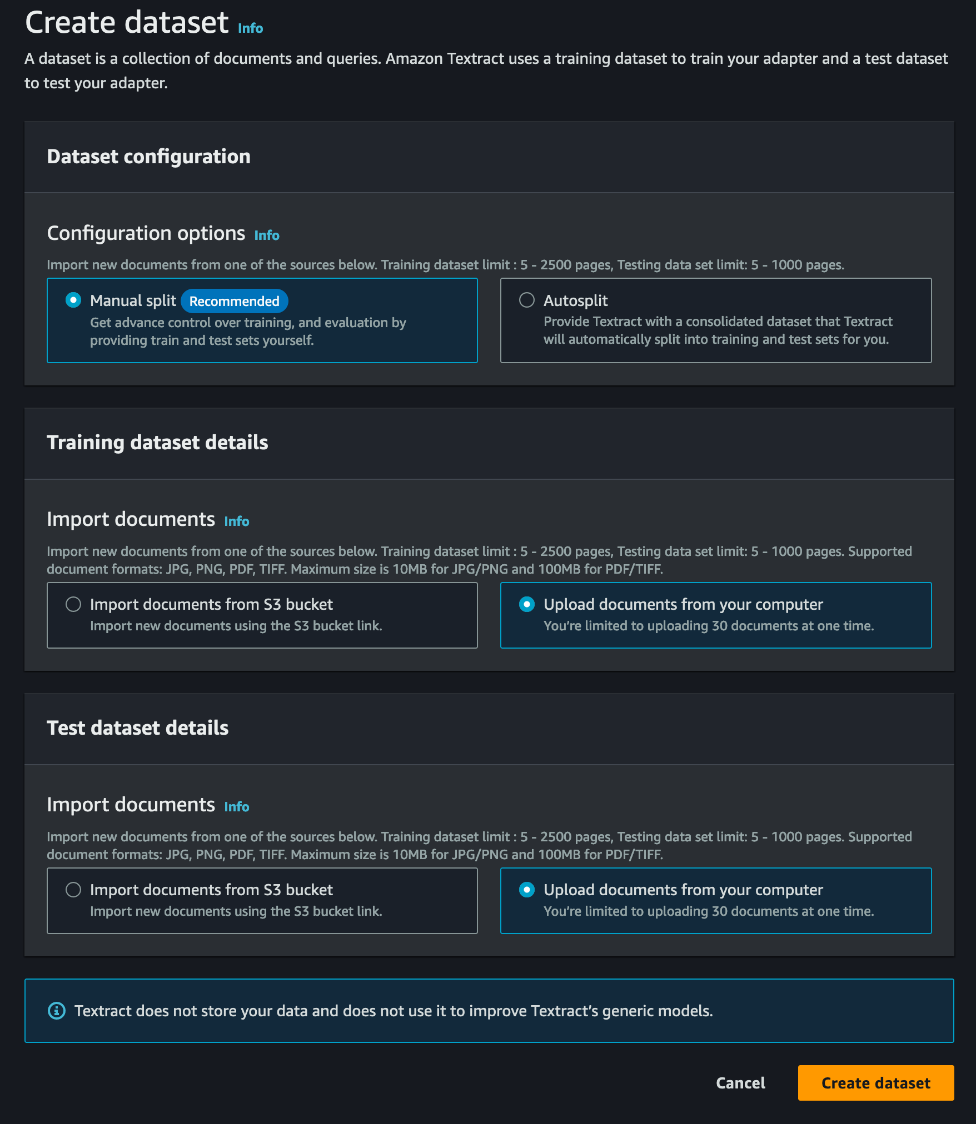
It’s important to note that you can construct an adapter with as few as five test and five training samples, but it’s essential to ensure that this sample set is diverse and representative of the workload encountered in a production environment.
For this tutorial, we have curated sample check datasets that you can download. Our dataset includes variations such as personal checks, cashier’s checks, stimulus checks and checks embedded within pay stubs. We also included handwritten and printed checks; along with variations in fields such as the memo line.
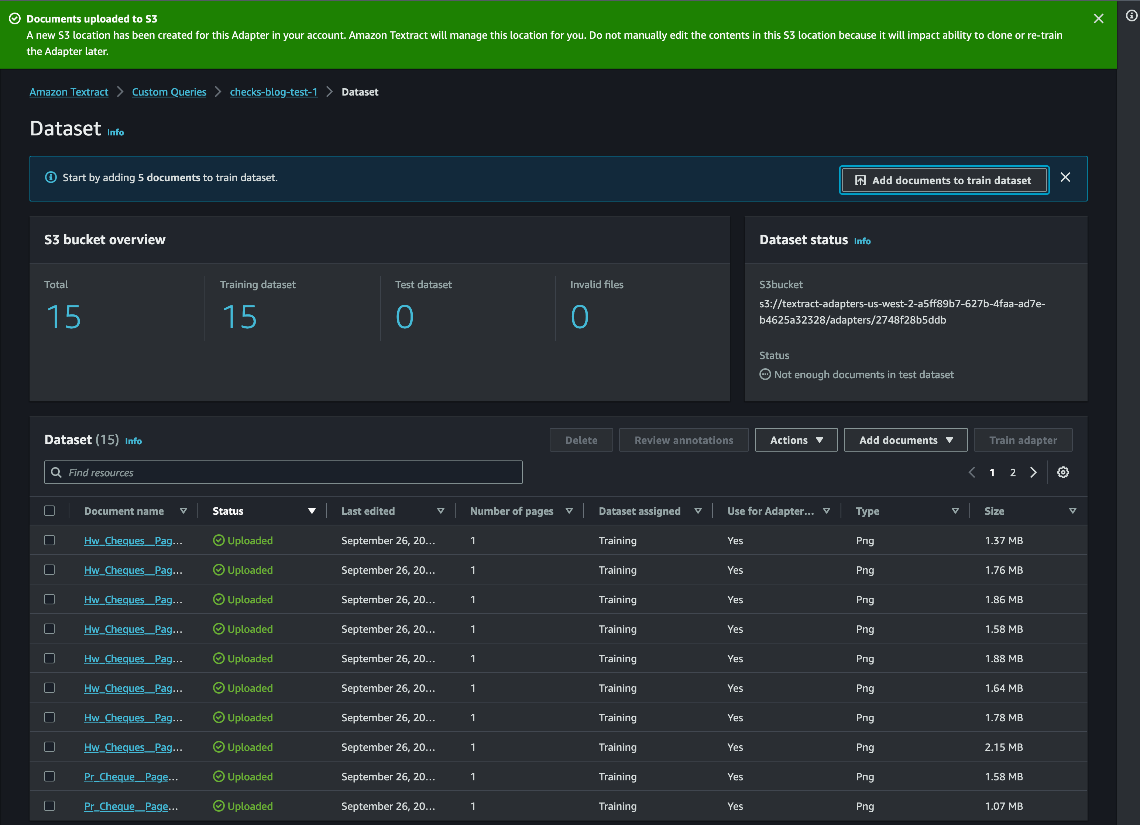
Annotate sample documents
As a next step, you annotate the sample documents by associating queries with their corresponding answers via the console. You can initiate annotation via auto labeling or manual labeling. Auto labeling uses Amazon Textract Queries to pre-label the dataset. We recommend using auto labeling to fast-track the annotation process.
For this checks processing use case, we use the following queries. If your use case involves other document types, refer to Best Practices for Queries to draft queries applicable to your use case.
- Who is the payee?
- What is the check#?
- What is the payee address?
- What is the date?
- What is the account#?
- What is the check amount in words?
- What is the account name/payer/drawer name?
- What is the dollar amount?
- What is the bank name/drawee name?
- What is the bank routing number?
- What is the MICR line?
- What is the memo?
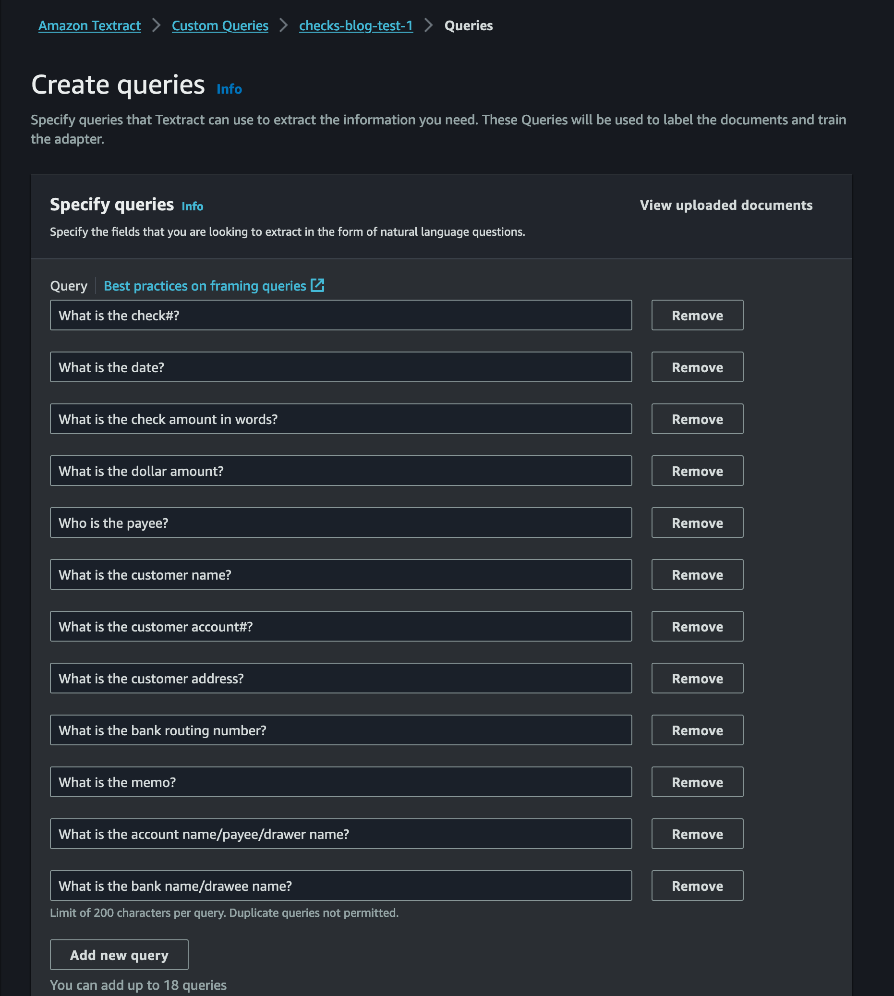
When the auto labeling process is complete, you have the option to review and make edits to the answers provided for each document. Choose Start reviewing to review the annotations against each image.

If the response to a query is missing or wrong, you can add or edit the response either by drawing a bounding box or entering the response manually.
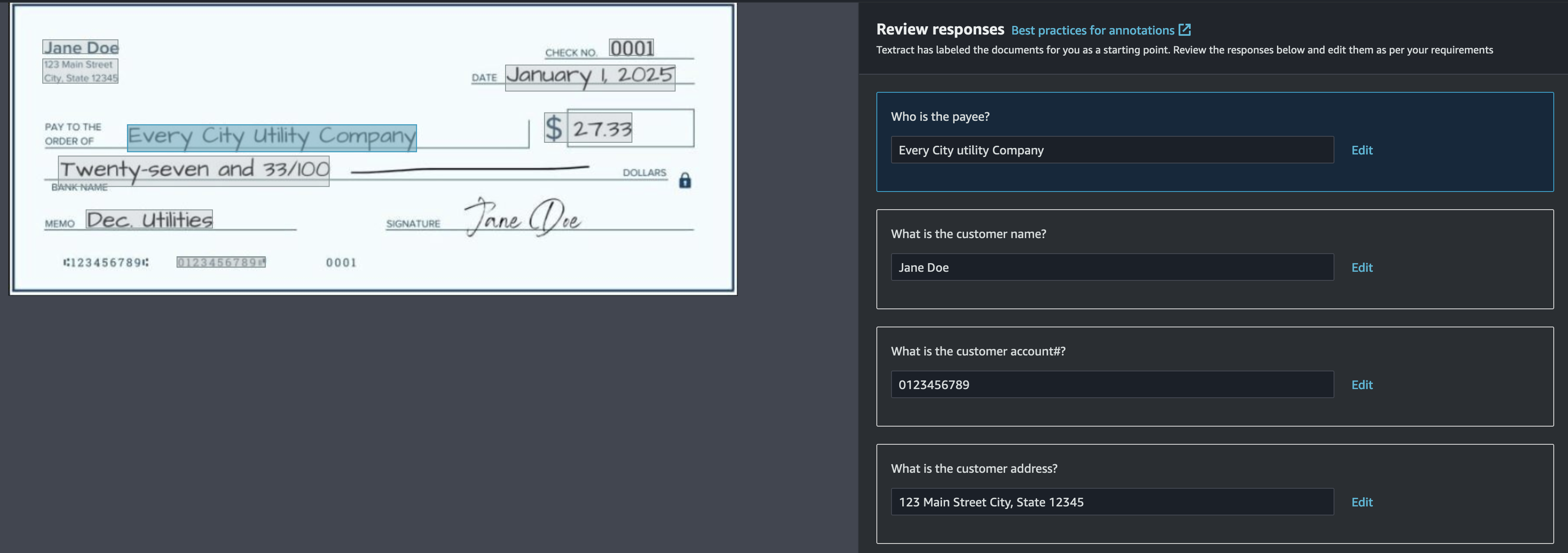
To accelerate your walkthrough, we have pre-annotated the checks samples for you to copy to your AWS account. Run the custom-queries-checks-blog.ipynb Jupyter notebook within the Amazon Textract code samples library to automatically update your annotations.
Train the adapter
After you’ve reviewed all the sample documents to ensure the accuracy of the annotations, you can begin the adapter training process. During this step, you need to designate a storage location where the adapter should be saved. The duration of the training process will vary depending on the size of the dataset utilized for training. The training API can also be invoked programmatically if you choose to use an annotation tool of your own choice and pass the relevant input files to the API. Refer to Custom Queries for more details.

Evaluate performance metrics
After the adapter has completed training, you can assess its performance by examining evaluation metrics such as F1 score, precision, and recall. You can analyze these metrics either collectively or on a per-document basis. Using our sample checks dataset, you will see the accuracy metric (F1 score) improve from 68% to 92% with the trained adapter.

Additionally, you can test the adapter’s output on new documents by choosing Try Adapter.

Following the evaluation, you can choose to enhance the adapter’s performance by either incorporating additional sample documents into the training dataset or by re-annotating documents with scores that are lower than your threshold. To re-annotate documents, choose Verify documents on the adapter details page, select the document, and choose Review annotations.
Programmatically test the adapter
With the training successfully completed, you can now use the adapter in your AnalyzeDocument API calls. The API request is similar to the Amazon Textract Queries API request, with the addition of the AdaptersConfig object.
You can run the following sample code or directly run it within the custom-queries-checks-blog.ipynb Jupyter notebook. The sample notebook also provides code to compare results between Amazon Textract Queries and Amazon Textract Custom Queries.
Create an AdaptersConfig object with the adapter ID and adapter version, and optionally include the pages you want the adapter to be applied to:
Create a QueriesConfig object with the queries you trained the adapter with and call the Amazon Textract API. Note that you can also include additional queries that the adapter has not been trained on. Amazon Textract will automatically use the Queries feature for these questions and not Custom Queries, thereby providing you with the flexibility of using Custom Queries only where needed.
Finally, we tabulate our results for better readability:
Clean up
To clean up your resources, complete the following steps:
- On the Amazon Textract console, choose Custom Queries in the navigation pane.
- Select the adaptor you want to delete.
- Choose Delete.
Adapter management
You can regularly improve your adapters by creating new versions of a previously generated adapter. To create a new version of an adapter, you add new sample documents to an existing adapter, label the documents, and perform training. You can simultaneously maintain multiple versions of an adapter for use in your development pipelines. To update your adapters seamlessly, do not make changes to or delete your Amazon Simple Storage Service (Amazon S3) bucket where the files needed for adapter generation are saved.
Best practices
When using Custom Queries on your documents, refer to Best practices for Amazon Textract Custom Queries for additional considerations and best practices.
Benefits of Custom Queries
Custom Queries offers the following benefits:
- Enhanced document understanding – Through its ability to extract and normalize data with high accuracy, Custom Queries reduces reliance on manual reviews, and audits, and enables you to build more reliable automation for your intelligent document processing workflows.
- Faster time to value – When you encounter new document types where you need higher accuracy, you can use Custom Queries to generate an adapter in a self-service manner within a few hours. You don’t have to wait for a pre-trained model update when you encounter new document types or variations of existing ones in your workflow. You have complete control over your pipeline and don’t need to depend on Amazon Textract to support your new document types.
- Data privacy – Custom Queries does not retain or use the data employed in generating adapters to enhance our general pretrained models available to all customers. The adapter is limited to the customer’s account or other accounts explicitly designated by the customer, ensuring that only such accounts can access the improvements made using the customer’s data.
- Convenience –Custom Queries provides a fully managed inference experience similar to Queries. The adapter training is free and you will only pay for inference. Custom Queries saves you the overhead and expenses of training and operating custom models.
Conclusion
In this post, we discussed the benefits of Custom Queries, showed how Custom Queries can accurately extract data from checks, and shared best practices for effectively utilizing this feature. In just a few hours, you can create an adapter using the console and use it in the AnalyzeDocument API for your data extraction needs. For more information, refer to Custom Queries.
About the authors
 Shibin Michaelraj is a Sr. Product Manager with the Amazon Textract team. He is focused on building AI/ML-based products for AWS customers. He is excited helping customers solve their complex business challenges by leveraging AI and ML technologies. In his spare time, he enjoys running, tuning into podcasts, and refining his amateur tennis skills.
Shibin Michaelraj is a Sr. Product Manager with the Amazon Textract team. He is focused on building AI/ML-based products for AWS customers. He is excited helping customers solve their complex business challenges by leveraging AI and ML technologies. In his spare time, he enjoys running, tuning into podcasts, and refining his amateur tennis skills.
 Keith Mascarenhas is a Sr. Solutions Architect with the Amazon Textract service team. He is passionate about solving business problems at scale using machine learning, and currently helps our worldwide customers automate their document processing to achieve faster time to market with reduced operational costs.
Keith Mascarenhas is a Sr. Solutions Architect with the Amazon Textract service team. He is passionate about solving business problems at scale using machine learning, and currently helps our worldwide customers automate their document processing to achieve faster time to market with reduced operational costs.





