A successful deployment of a machine learning (ML) model in a production environment heavily relies on an end-to-end ML pipeline. Although developing such a pipeline can be challenging, it becomes even more complex when dealing with an edge ML use case. Machine learning at the edge is a concept that brings the capability of running ML models locally to edge devices. In order to deploy, monitor, and maintain these models at the edge, a robust MLOps pipeline is required. An MLOps pipeline allows to automate the full ML lifecycle from data labeling to model training and deployment.
Implementing an MLOps pipeline at the edge introduces additional complexities that make the automation, integration, and maintenance processes more challenging due to the increased operational overhead involved. However, using purpose-built services like Amazon SageMaker and AWS IoT Greengrass allows you to significantly reduce this effort. In this series, we walk you through the process of architecting and building an integrated end-to-end MLOps pipeline for a computer vision use case at the edge using SageMaker, AWS IoT Greengrass, and the AWS Cloud Development Kit (AWS CDK).
This post focuses on designing the overall MLOps pipeline architecture; Part 2 and Part 3 of this series focus on the implementation of the individual components. We have provided a sample implementation in the accompanying MLOps at the edge with Amazon SageMaker Edge Manager and AWS IoT Greengrass for an overview and reference architecture.
Use case: Inspecting the quality of metal tags
As an ML engineer, it’s important to understand the business case you are working on. So before we dive into the MLOps pipeline architecture, let’s look at the sample use case for this post. Imagine a production line of a manufacturer that engraves metal tags to create customized luggage tags. The quality assurance process is costly because the raw metal tags need to be inspected manually for defects like scratches. To make this process more efficient, we use ML to detect faulty tags early in the process. This helps avoid costly defects at later stages of the production process. The model should identify possible defects like scratches in near-real time and mark them. In manufacturing shop floor environments, you often have to deal with no connectivity or constrained bandwidth and increased latency. Therefore, we want to implement an on-edge ML solution for visual quality inspection that can run inference locally on the shop floor and decrease the requirements in regards to connectivity. To keep our example straightforward, we train a model that marks detected scratches with bounding boxes. The following image is an example of a tag from our dataset with three scratches marked.

Defining the pipeline architecture
We have now gained clarity into our use case and the specific ML problem we aim to address, which revolves around object detection at the edge. Now it’s time to draft an architecture for our MLOps pipeline. At this stage, we aren’t looking at technologies or specific services yet, but rather the high-level components of our pipeline. In order to quickly retrain and deploy, we need to automate the whole end-to-end process: from data labeling, to training, to inference. However, there are a few challenges that make setting up a pipeline for an edge case particularly hard:
- Building different parts of this process requires different skill sets. For instance, data labeling and training has a strong data science focus, edge deployment requires an Internet of Things (IoT) specialist, and automating the whole process is usually done by someone with a DevOps skill set.
- Depending on your organization, this whole process might even be implemented by multiple teams. For our use case, we’re working under the assumption that separate teams are responsible for labeling, training, and deployment.
- More roles and skill sets mean different requirements when it comes to tooling and processes. For instance, data scientists might want to monitor and work with their familiar notebook environment. MLOps engineers want to work using infrastructure as code (IaC) tools and might be more familiar with the AWS Management Console.
What does this mean for our pipeline architecture?
Firstly, it’s crucial to clearly define the major components of the end-to-end system that allows different teams to work independently. Secondly, well-defined interfaces between teams must be defined to enhance collaboration efficiency. These interfaces help minimize disruptions between teams, enabling them to modify their internal processes as needed as long as they adhere to the defined interfaces. The following diagram illustrates what this could look like for our computer vision pipeline.
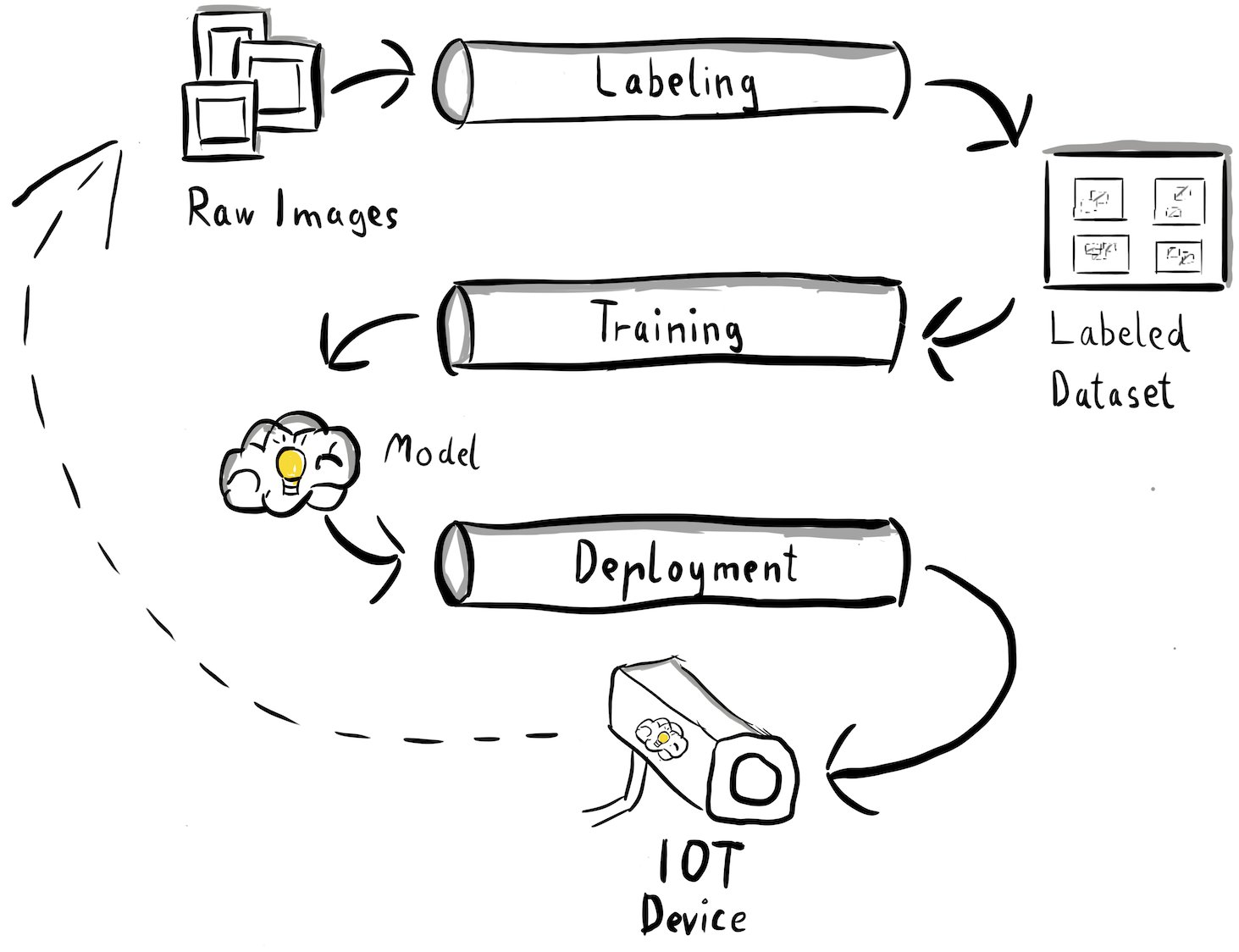
Let’s examine the overall architecture of the MLOps pipeline in detail:
- The process begins with a collection of raw images of metal tags, which are captured using an edge camera device in the production environment to form an initial training dataset.
- The next step involves labeling these images and marking defects using bounding boxes. It’s essential to version the labeled dataset, ensuring traceability and accountability for the utilized training data.
- After we have a labeled dataset, we can proceed with training, fine-tuning, evaluating, and versioning our model.
- When we’re happy with our model performance, we can deploy the model to an edge device and run live inferences at the edge.
- While the model operates in production, the edge camera device generates valuable image data containing previously unseen defects and edge cases. We can use this data to further enhance our model’s performance. To accomplish this, we save images for which the model predicts with low confidence or makes erroneous predictions. These images are then added back to our raw dataset, initiating the entire process again.
It’s important to note that the raw image data, labeled dataset, and trained model serve as well-defined interfaces between the distinct pipelines. MLOps engineers and data scientists have the flexibility to choose the technologies within their pipelines as long as they consistently produce these artifacts. Most significantly, we have established a closed feedback loop. Faulty or low-confidence predictions made in production can be used to regularly augment our dataset and automatically retrain and enhance the model.
Target architecture
Now that the high-level architecture is established, it’s time to go one level deeper and look at how we could build this with AWS services. Note that the architecture shown in this post assumes you want to take full control of the whole data science process. However, if you’re just getting started with quality inspection at the edge, we recommend Amazon Lookout for Vision. It provides a way to train your own quality inspection model without having to build, maintain, or understand ML code. For more information, refer to Amazon Lookout for Vision now supports visual inspection of product defects at the edge.
However, if you want to take full control, the following diagram shows what an architecture could look like.
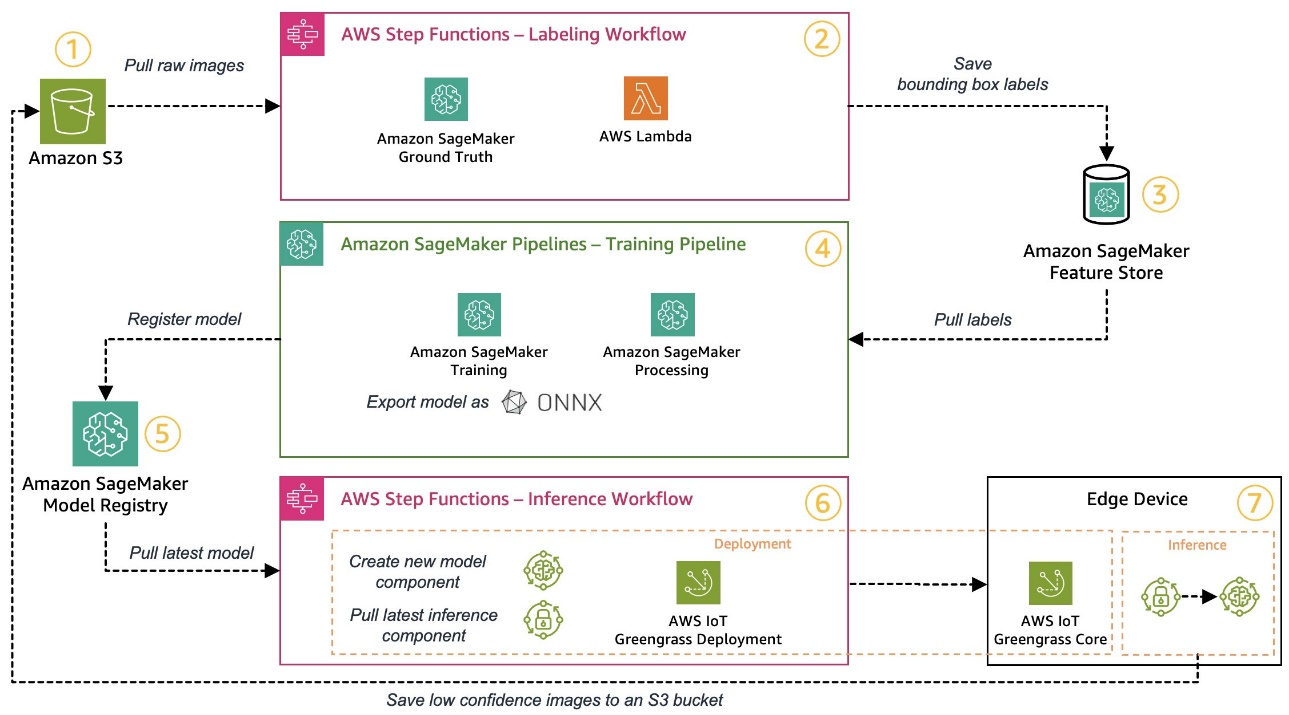
Similar to before, let’s walk through the workflow step by step and identify which AWS services suit our requirements:
- Amazon Simple Storage Service (Amazon S3) is used to store raw image data because it provides us with a low-cost storage solution.
- The labeling workflow is orchestrated using AWS Step Functions, a serverless workflow engine that makes it easy to orchestrate the steps of the labeling workflow. As part of this workflow, we use Amazon SageMaker Ground Truth to fully automate the labeling using labeling jobs and managed human workforces. AWS Lambda is used to prepare the data, start the labeling jobs, and store the labels in Amazon SageMaker Feature Store.
- SageMaker Feature Store stores the labels. It allows us to centrally manage and share our features and provides us with built-in data versioning capabilities, which makes our pipeline more robust.
- We orchestrate the model building and training pipeline using Amazon SageMaker Pipelines. It integrates with the other SageMaker features required via built-in steps. SageMaker Training jobs are used to automate the model training, and SageMaker Processing jobs are used to prepare the data and evaluate model performance. In this example, we’re using the Ultralytics YOLOv8 Python package and model architecture to train and export an object detection model to the ONNX ML model format for portability.
- If the performance is acceptable, the trained model is registered in Amazon SageMaker Model Registry with an incremental version number attached. It acts as our interface between the model training and edge deployment steps. We also manage the approval state of models here. Similar to the other services used, it’s fully managed, so we don’t have to take care of running our own infrastructure.
- The edge deployment workflow is automated using Step Functions, similar to the labeling workflow. We can use the API integrations of Step Functions to easily call the various required AWS service APIs like AWS IoT Greengrass to create new model components and afterwards deploy the components to the edge device.
- AWS IoT Greengrass is used as the edge device runtime environment. It manages the deployment lifecycle for our model and inference components at the edge. It allows us to easily deploy new versions of our model and inference components using simple API calls. In addition, ML models at the edge usually don’t run in isolation; we can use the various AWS and community provided components of AWS IoT Greengrass to connect to other services.
The architecture outlined resembles our high-level architecture shown before. Amazon S3, SageMaker Feature Store, and SageMaker Model Registry act as the interfaces between the different pipelines. To minimize the effort to run and operate the solution, we use managed and serverless services wherever possible.
Merging into a robust CI/CD system
The data labeling, model training, and edge deployment steps are core to our solution. As such, any change related to the underlying code or data in any of those parts should trigger a new run of the whole orchestration process. To achieve this, we need to integrate this pipeline into a CI/CD system that allows us to automatically deploy code and infrastructure changes from a versioned code repository into production. Similar to the previous architecture, team autonomy is an important aspect here. The following diagram shows what this could look like using AWS services.
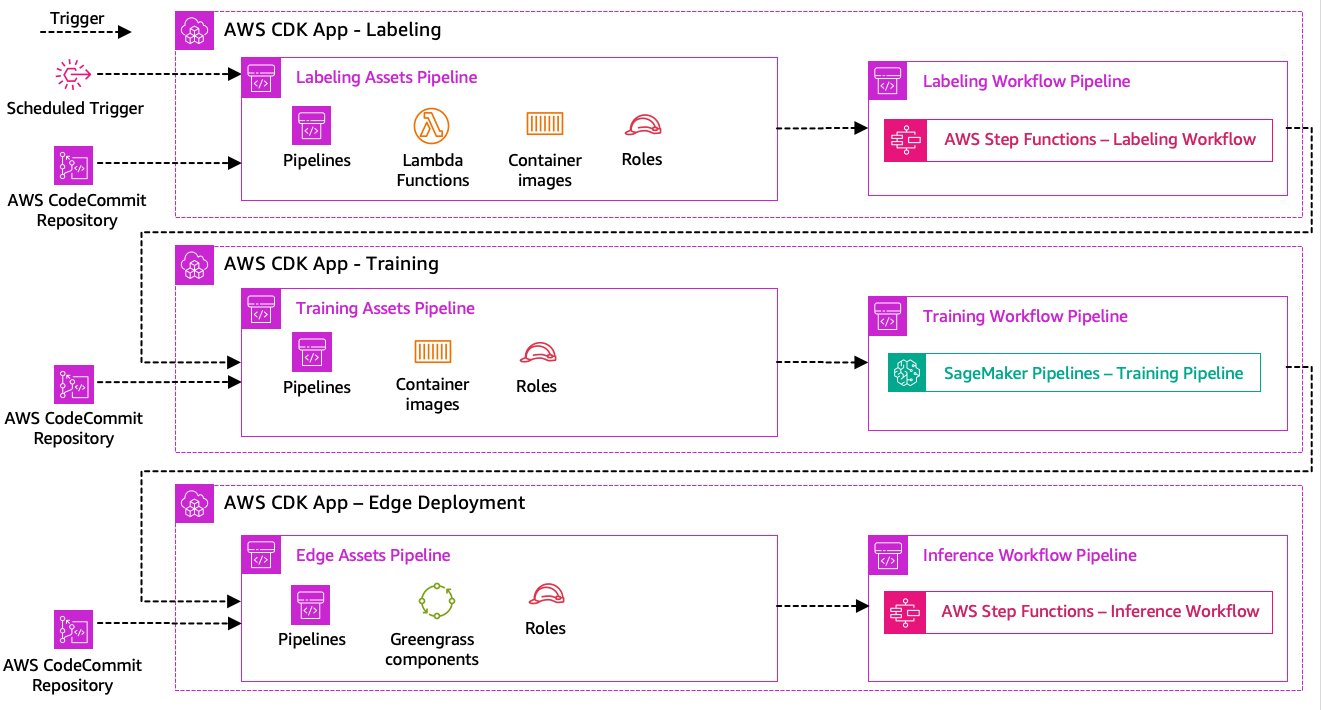
Let’s walk through the CI/CD architecture:
- AWS CodeCommit acts as our Git repository. For the sake of simplicity, in our provided sample, we separated the distinct parts (labeling, model training, edge deployment) via subfolders in a single git repository. In a real-world scenario, each team might use different repositories for each part.
- Infrastructure deployment is automated using the AWS CDK and each part (labeling, training, and edge) gets its own AWS CDK app to allow independent deployments.
- The AWS CDK pipeline feature uses AWS CodePipeline to automate the infrastructure and code deployments.
- The AWS CDK deploys two code pipelines for each step: an asset pipeline and a workflow pipeline. We separated the workflow from the asset deployment to allow us to start the workflows separately in case there are no asset changes (for example, when there are new images available for training).
- The asset code pipeline deploys all infrastructure required for the workflow to run successfully, such as AWS Identity and Access Management (IAM) roles, Lambda functions, and container images used during training.
- The workflow code pipeline runs the actual labeling, training, or edge deployment workflow.
- Asset pipelines are automatically triggered on commit as well as when a previous workflow pipeline is complete.
- The whole process is triggered on a schedule using an Amazon EventBridge rule for regular retraining.
With the CI/CD integration, the whole end-to-end chain is now fully automated. The pipeline is triggered whenever code changes in our git repository as well as on a schedule to accommodate for data changes.
Thinking ahead
The solution architecture described represents the basic components to build an end-to-end MLOps pipeline at the edge. However, depending on your requirements, you might think about adding additional functionality. The following are some examples:
Conclusion
In this post, we outlined our architecture for building an end-to-end MLOps pipeline for visual quality inspection at the edge using AWS services. This architecture streamlines the entire process, encompassing data labeling, model development, and edge deployment, enabling us to swiftly and reliably train and implement new versions of the model. With serverless and managed services, we can direct our focus towards delivering business value rather than managing infrastructure.
In Part 2 of this series, we will delve one level deeper and look at the implementation of this architecture in more detail, specifically labeling and model building. If you want to jump straight to the code, you can check out the accompanying GitHub repo.
About the authors
 Michael Roth is a Senior Solutions Architect at AWS supporting Manufacturing customers in Germany to solve their business challenges through AWS technology. Besides work and family he’s interested in sports cars and enjoys Italian coffee.
Michael Roth is a Senior Solutions Architect at AWS supporting Manufacturing customers in Germany to solve their business challenges through AWS technology. Besides work and family he’s interested in sports cars and enjoys Italian coffee.
 Jörg Wöhrle is a Solutions Architect at AWS, working with manufacturing customers in Germany. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life. Beyond cloud, he’s an ambitious runner and enjoys quality time with his family. So if you have a DevOps challenge or want to go for a run: let him know.
Jörg Wöhrle is a Solutions Architect at AWS, working with manufacturing customers in Germany. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life. Beyond cloud, he’s an ambitious runner and enjoys quality time with his family. So if you have a DevOps challenge or want to go for a run: let him know.
 Johannes Langer is a Senior Solutions Architect at AWS, working with enterprise customers in Germany. Johannes is passionate about applying machine learning to solve real business problems. In his personal life, Johannes enjoys working on home improvement projects and spending time outdoors with his family.
Johannes Langer is a Senior Solutions Architect at AWS, working with enterprise customers in Germany. Johannes is passionate about applying machine learning to solve real business problems. In his personal life, Johannes enjoys working on home improvement projects and spending time outdoors with his family.





