Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Layout is a new feature that allows customers to automatically extract layout elements such as paragraphs, titles, subtitles, headers, footers, and more from documents. Layout extends Amazon Textract’s word and line detection by automatically grouping the text into these layout elements and sequencing them according to human reading patterns. (That is, reading order from left to right and top to bottom.).
Building document processing and understanding solutions for financial and research reports, medical transcriptions, contracts, media articles, and so on requires extraction of information present in titles, headers, paragraphs, and so on. For example, when cataloging financial reports in a document database, extracting and storing the title as a catalog index enables easy retrieval. Prior to the introduction of this feature, customers had to construct these elements using post-processing code and the words and lines response from Amazon Textract.
The complexity of implementing this code is amplified with documents with multiple columns and complex layouts. With this announcement, extraction of commonly occurring layout elements from documents becomes easier and allows customers to build efficient document processing solutions faster with less code.
In Sept 2023, Amazon Textract launched the Layout feature that automatically extracts layout elements such as paragraphs, titles, lists, headers, and footers and orders the text and elements as a human would read. We also released the updated version of the open source postprocessing toolkit, purpose-built for Amazon Textract, known as Amazon Textract Textractor.
In this post, we discuss how customers can take advantage of this feature for document processing workloads. We also discuss a qualitative study demonstrating how Layout improves generative artificial intelligence (AI) task accuracy for both abstractive and extractive tasks for document processing workloads involving large language models (LLMs).
Layout elements
Central to the Layout feature of Amazon Textract are the new Layout elements. The LAYOUT feature of AnalyzeDocument API can now detect up to ten different layout elements in a document’s page. These layout elements are represented as block type in the response JSON and contain the confidence, geometry (that is, bounding box and polygon information), and Relationships, which is a list of IDs corresponding to the LINE block type.
- Title – The main title of the document. Returned as
LAYOUT_TITLEblock type. - Header – Text located in the top margin of the document. Returned as
LAYOUT_HEADERblock type. - Footer – Text located in the bottom margin of the document. Returned as
LAYOUT_FOOTERblock type. - Section Title – The titles below the main title that represent sections in the document. Returned as
LAYOUT_SECTION_HEADERblock type. - Page Number – The page number of the documents. Returned as
LAYOUT_PAGE_NUMBERblock type. - List – Any information grouped together in list form. Returned as
LAYOUT_LISTblock type. - Figure – Indicates the location of an image in a document. Returned as
LAYOUT_FIGUREblock type. - Table – Indicates the location of a table in the document. Returned as
LAYOUT_TABLEblock type. - Key Value – Indicates the location of form key-value pairs in a document. Returned as
LAYOUT_KEY_VALUEblock type. - Text – Text that is present typically as a part of paragraphs in documents. It is a catch all for text that is not present in other elements. Returned as
LAYOUT_TEXTblock type.

Each layout element may contain one or more LINE relationships, and these lines constitute the actual textual content of the layout element (for example, LAYOUT_TEXT is typically a paragraph of text containing multiple LINEs). It is important to note that layout elements appear in the correct reading order in the API response as the reading order in the document, which makes it easy to construct the layout text from the API’s JSON response.
Use cases of layout-aware extraction
Following are some of the common use cases for the new AnalyzeDocument LAYOUT feature.
- Extracting layout elements for search indexing and cataloging purposes. The contents of the
LAYOUT_TITLEorLAYOUT_SECTION_HEADER, along with the reading order, can be used to appropriately tag or enrich metadata. This improves the context of a document in a document repository to improve search capabilities or organize documents. - Summarize the entire document or parts of a document by extracting text in proper reading order and using the layout elements.
- Extracting specific parts of the document. For example, a document may contain a mix of images with text within it and other plaintext sections or paragraphs. You can now isolate the text sections using the
LAYOUT_TEXTelement. - Better performance and accurate answers for in-context document Q&A and entity extractions using an LLM.
There are other possible document automation use cases where Layout can be useful. However, in this post we explain how to extract layout elements in order to help understand how to use the feature for traditional documentation automation solutions. We discuss the benefits of using Layout for a document Q&A use case with LLMs using a common method known as Retrieval Augmented Generation (RAG), and for entity extraction use-case. For the outcomes of both of these use-cases, we present comparative scores that helps differentiate the benefits of layout aware text as opposed to just plaintext.
To highlight the benefits, we ran tests to compare how plaintext extracted using raster scans with DetectDocumentText and layout-aware linearized text extracted using AnalyzeDocument with LAYOUT feature impacts the outcome of in-context Q&A outputs by an LLM. For this test, we used Anthropic’s Claude Instant model with Amazon Bedrock. However, for complex document layouts, the generation of text in proper reading order and subsequently chunking them appropriately may be challenging, depending on how complex the document layout is. In the following sections, we discuss how to extract layout elements, and linearize the text to build an LLM-based application. Specifically, we discuss the comparative evaluation of the responses generated by the LLM for document Q&A application using raster scan–based plaintext and layout-aware linearized text.
Extracting layout elements from a page
The Amazon Textract Textractor toolkit can process a document through the AnalyzeDocument API with LAYOUT feature and subsequently exposes the detected layout elements through the page’s PAGE_LAYOUT property and its own subproperty TITLES, HEADERS, FOOTERS, TABLES, KEY_VALUES, PAGE_NUMBERS, LISTS, and FIGURES. Each element has its own visualization function, allowing you to see exactly what was detected. To get started, you start by installing Textractor using
As demonstrated in the following code snippet, the document news_article.pdf is processed with the AnalyzeDocument API with LAYOUT feature. The response results in a variable document that contains each of the detected Layout blocks from the properties.

See a more in-depth example in the official Textractor documentation.
Linearizing text from the layout response
To use the layout capabilities, Amazon Textract Textractor was extensively reworked for the 1.4 release to provide linearization with over 40 configuration options, allowing you to tailor the linearized text output to your downstream use case with little effort. The new linearizer supports all currently available AnalyzeDocument APIs, including forms and signatures, which lets you add selection items to the resulting text without making any code changes.
See this example and more in the official Textractor documentation.
We have also added a layout pretty printer to the library that allows you to call a single function by passing in the layout API response in JSON format and get the linearized text (by page) in return.
You have the option to format the text in markdown format, exclude text from within figures in the document, and exclude page header, footer, and page number extractions from the linearized output. You can also store the linearized output in plaintext format in your local file system or in an Amazon S3 location by passing the save_txt_path parameter. The following code snippet demonstrates a sample usage –
Evaluating LLM performing metrics for abstractive and extractive tasks
Layout-aware text is found to improve the performance and quality of text generated by LLMs. In particular, we evaluate two types of LLM tasks—abstractive and extractive tasks.
Abstractive tasks refer to assignments that require the AI to generate new text that is not directly found in the source material. Some examples of abstractive task include summarization and question answering. For these tasks, we use the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metric to evaluate the performance of an LLM on question-answering tasks with respect to a set of ground truth data.
Extractive tasks refer to activities where the model identifies and extracts specific portions of the input text to construct a response. In these tasks, the model is focused on selecting relevant segments (such as sentences, phrases, or keywords) from the source material rather than generating new content. Some examples are named entity recognition (NER) and keyword extraction. For these tasks, we use Average Normalized Levenshtein Similarity (ANLS) on named entity recognition tasks based on the layout-linearized text extracted by Amazon Textract.
ROUGE score analysis on abstractive question-answering task
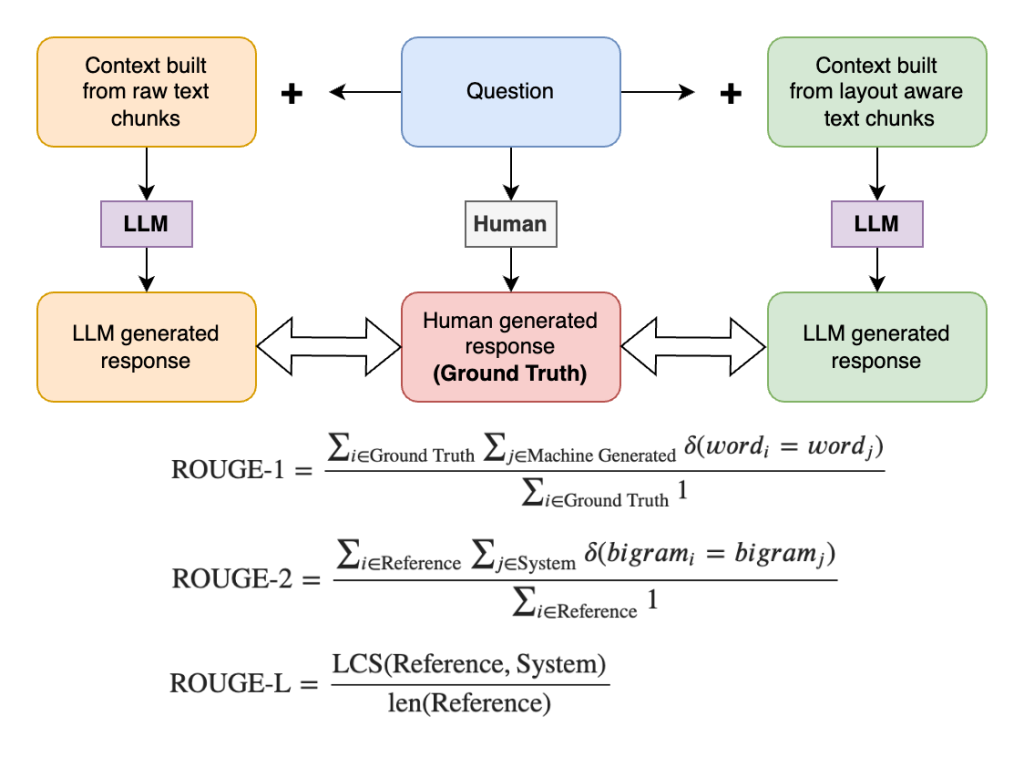
Our test is set up to perform in-context Q&A on a multicolumn document by extracting the text and then performing RAG to get answer responses from the LLM. We perform Q&A on a set of questions using the raster scan–based raw text and layout-aware linearized text. We then evaluate ROUGE metrics for each question by comparing the machine-generated response to the corresponding ground truth answer. In this case, the ground truth is the same set of questions answered by a human, which is considered as a control group.
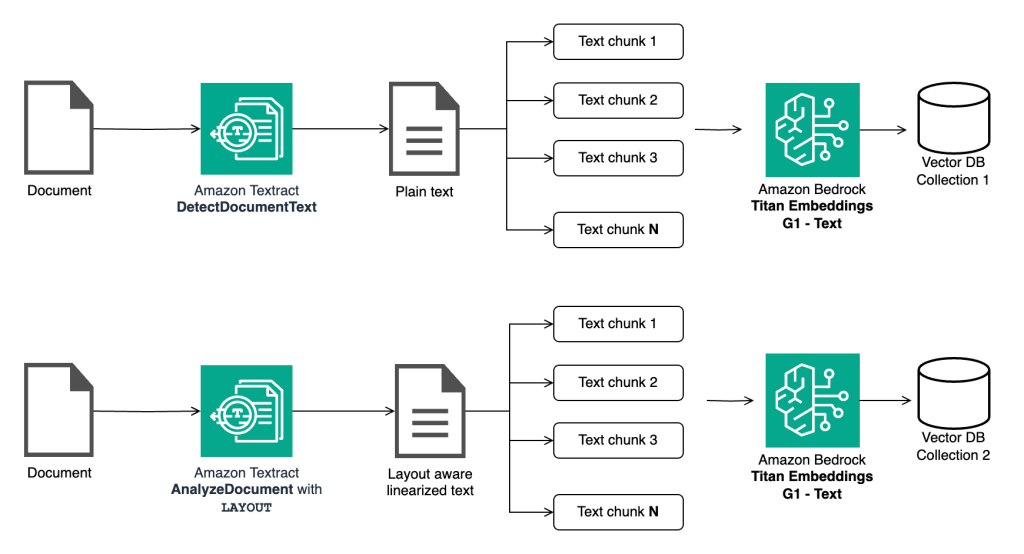
In-context Q&A with RAG requires extracting text from the document, creating smaller chunks of the text, generating vector embeddings of the chunks, and subsequently storing them in a vector database. This is done so that the system can perform a relevance search with the question on the vector database to return chunks of text that are most relevant to the question being asked. These relevant chunks are then used to build the overall context and provided to the LLM so that it can accurately answer the question.
The following document, taken from the DocUNet: Document Image Unwarping via a Stacked U-Net dataset, is used for the test. This document is a multicolumn document with headers, titles, paragraphs, and images. We also defined a set of 20 questions answered by a human as a control group or ground truth. The same set of 20 questions was then used to generate responses from the LLM.

In the next step, we extract the text from this document using DetectDocumentText API and AnalyzeDocument API with LAYOUT feature. Since most LLMs have a limited token context window, we kept the chunk size small, about 250 characters with a chunk overlap of 50 characters, using LangChain’s RecursiveCharacterTextSplitter. This resulted in two separate sets of document chunks—one generated using the raw text and the other using the layout-aware linearized text. Both sets of chunks were stored in a vector database by generating vector embeddings using the Amazon Titan Embeddings G1 Text embedding model.
The following code snippet generates the raw text from the document.
The output (trimmed for brevity) looks like the following. The text reading order is incorrect due to the lack of layout awareness of the API, and the extracted text spans the text columns.
The visual of the reading order for raw text extracted by DetectDocumentText can be seen in the following image.

The following code snippet generates the layout-linearized text from the document. You can use either method to generate the linearized text from the document using the latest version of Amazon Textract Textractor Python library.
The output (trimmed for brevity) looks like the following. The text reading order is preserved since we used the LAYOUT feature, and the text makes more sense.
The visual of the reading order for raw text extracted by AnalyzeDocument with LAYOUT feature can be seen in the following image.

We performed chunking on both the extracted text separately, with a chunk size of 250 and an overlap of 50.
Next, we generate vector embeddings for the chunks and load them into a vector database in two separate collections. We used open source ChromaDB as our in-memory vector database and used topK value of 3 for the relevance search. This means that for every question, our relevance search query with ChromaDB returns 3 relevant chunks of text of size 250 each. These three chunks are then used to build a context for the LLM. We intentionally chose a smaller chunk size and smaller topK to build the context for the following specific reasons.
- Shorten the overall size of our context since research suggests that LLMs tend to perform better with shorter context, even though the model supports longer context (through a larger token context window).
- Smaller overall prompt size results in lower overall text generation model latency. The larger the overall prompt size (which includes the context), the longer it may take the model to generate a response.
- Comply with the model’s limited token context window, as is the case with most LLMs.
- Cost efficiency since using fewer tokens means lower cost per question for input and output tokens combined.
Note that Anthropic Claude Instant v1 does support a 100,000 token context window via Amazon Bedrock. We intentionally limited ourselves to a smaller chunk size since that also makes the test relevant to models with fewer parameters and overall shorter context windows.
We used ROUGE metrics to evaluate machine-generated text against a reference text (or ground truth), measuring various aspects like the overlap of n-grams, word sequences, and word pairs between the two texts. We chose three ROUGE metrics for evaluation.
- ROUGE-1: Compares the overlap of unigrams (single words) between the generated text and a reference text.
- ROUGE-2: Compares the overlap of bigrams (two-word sequences) between the generated text and a reference text.
- ROUGE-L: Measures the longest common subsequence (LCS) between the generated text and a reference text, focusing on the longest sequence of words that appear in both texts, albeit not necessarily consecutively.
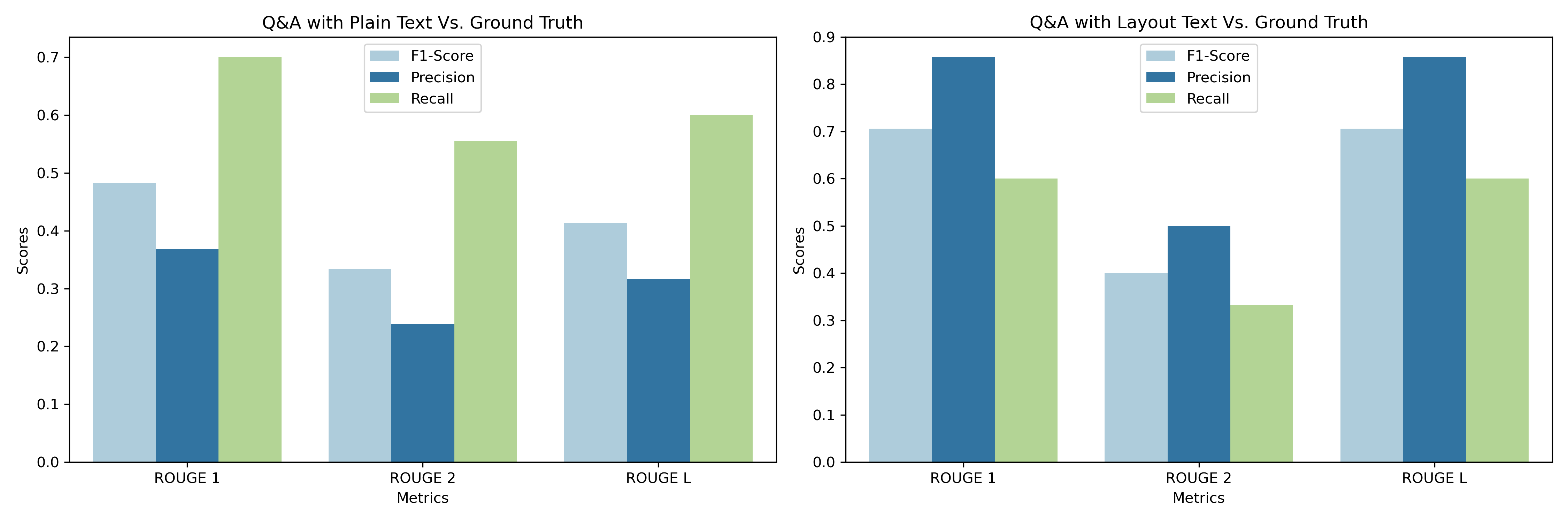
For our 20 sample questions relevant to the document, we ran Q&A with the raw text and linearized text, respectively, and then ran the ROUGE score analysis. We noticed almost 50 percent average improvement in precision overall. And there was significant improvement in F1-scores when layout-linearized text was compared to ground truth as opposed to when raw text was compared to ground truth.
This suggests that the model became better at generating correct responses with the help of linearized text and smaller chunking. This led to an increase in precision, and the balance between precision and recall shifted favorably towards precision, leading to an increase in the F1 score. The increased F1 score, which balances precision and recall, suggests an improvement. It’s essential to consider the practical implications of these metric changes. For instance, in a scenario where false positives are costly, the increase in precision is highly beneficial.
ANLS score analysis on extractive tasks over academic datasets
We measure the ANLS or the Average Normalized Levenshtein Similarity, which is an edit distance metric that was introduced by the paper Scene Text Visual Question Answering and aims to softly penalize minor OCR imperfections while considering the model’s reasoning abilities at the same time. This metric is a derivative version of traditional Levenshtein distance, which is a measure of the difference between two sequences (such as strings). It is defined as the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one word into the other.
For our ANLS tests, we performed an NER task where the LLM was prompted to extract the exact value from the OCR-extracted text. The two academic datasets used for the tests are DocVQA and InfographicVQA. We used zero-shot prompting to attempt extraction of key entities. The prompt used for the LLMs is of the following structure.
Accuracy improvements were observed in all document question-answering datasets tested with the open source FlanT5-XL model when using layout-aware linearized text, as opposed to raw text (raster scan), in response to zero-shot prompts. In the InfographicVQA dataset, using layout-aware linearized text enables the smaller 3B parameter FlanT5-XL model to match the performance of the larger FlanT5-XXL model (on raw text), which has nearly four times as many parameters (11B).
| Dataset | ANLS* | |||||
| FlanT5-XL (3B) | FlanT5-XXL (11B) | |||||
| Not Layout-aware (Raster) | Layout-aware | Δ | Not Layout- aware (Raster) | Layout-aware | Δ | |
| DocVQA | 66.03% | 68.46% | 1.43% | 70.71% | 72.05% | 1.34% |
| InfographicsVQA | 29.47% | 35.76% | 6.29% | 37.82% | 45.61% | 7.79% |
* ANLS is measured on text extracted by Amazon Textract, not the provided document transcription
Conclusion
The launch of Layout marks a significant advancement in using Amazon Textract to build document automation solutions. As discussed in this post, Layout uses traditional and generative AI methods to improve efficiencies when building a wide variety of document automation solutions such as document search, contextual Q&A, summarization, key-entities extraction, and more. As we continue to embrace the power of AI in building document processing and understanding systems, these enhancements will no doubt pave the way for more streamlined workflows, higher productivity, and more insightful data analysis.
For more information on the Layout feature and how to take advantage of the feature for document automation solutions, refer to AnalyzeDocument, Layout analysis, and Text linearization for generative AI applications documentation.
About the Authors
 Anjan Biswas is a Senior AI Services Solutions Architect who focuses on computer vision, NLP, and generative AI. Anjan is part of the worldwide AI services specialist team and works with customers to help them understand and develop solutions to business problems with AWS AI Services and generative AI.
Anjan Biswas is a Senior AI Services Solutions Architect who focuses on computer vision, NLP, and generative AI. Anjan is part of the worldwide AI services specialist team and works with customers to help them understand and develop solutions to business problems with AWS AI Services and generative AI.
 Lalita Reddi is a Senior Technical Product Manager with the Amazon Textract team. She is focused on building machine learning–based services for AWS customers. In her spare time, Lalita likes to play board games and go on hikes.
Lalita Reddi is a Senior Technical Product Manager with the Amazon Textract team. She is focused on building machine learning–based services for AWS customers. In her spare time, Lalita likes to play board games and go on hikes.
 Edouard Belval is a Research Engineer in the computer vision team at AWS. He is the main contributor behind the Amazon Textract Textractor library.
Edouard Belval is a Research Engineer in the computer vision team at AWS. He is the main contributor behind the Amazon Textract Textractor library.





